[3]:
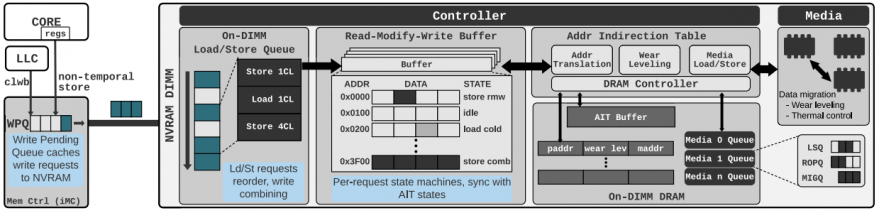
PM's archi:
Core -> LLC -> WPQ -> LSQ -> RMW Buffer -> AIT -> PCM media.
[5]:
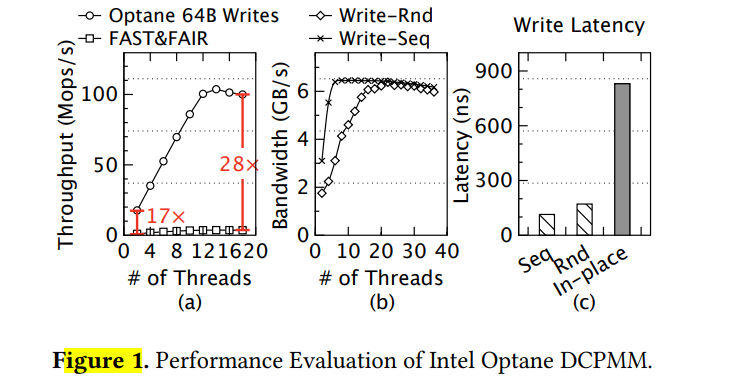
- Sequential and random access patterns have similar bandwidth under high concurrency.
- Repeat flush to the same cacheline is delayed dramatically.
[1]:
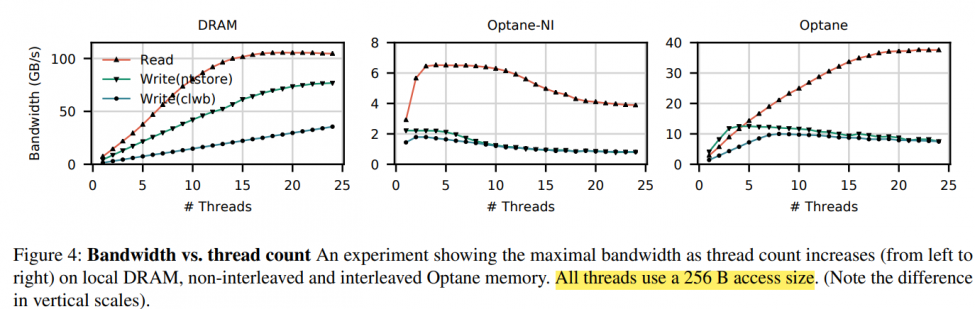
Optane-NI: single DIMM, Optane: 6 DIMMs.
note: you can find bandwidth and the number of DIMMs are almost linearly correlated (in such big workset which reduce the effects of cache). also tricky here, such random 256B write bandwidth didn't increase with concurrent accesses like [5].
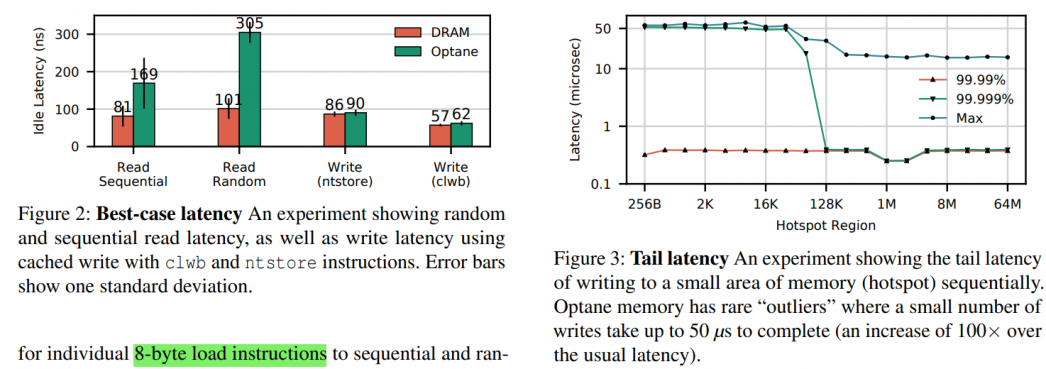
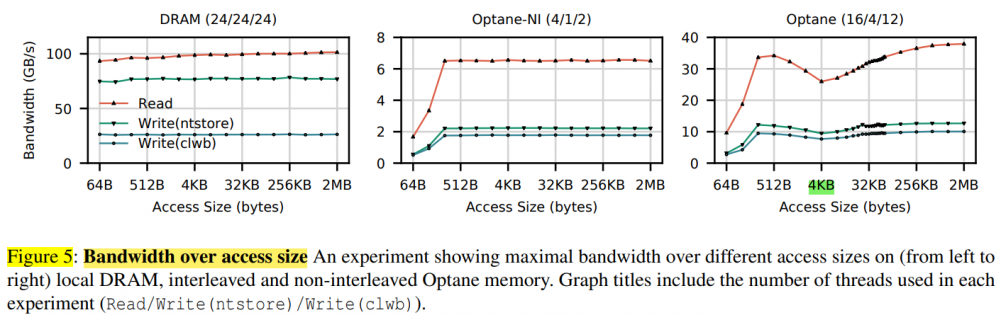
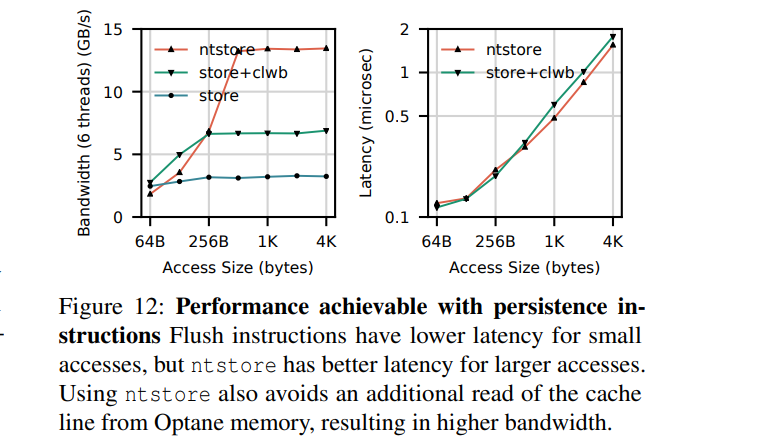
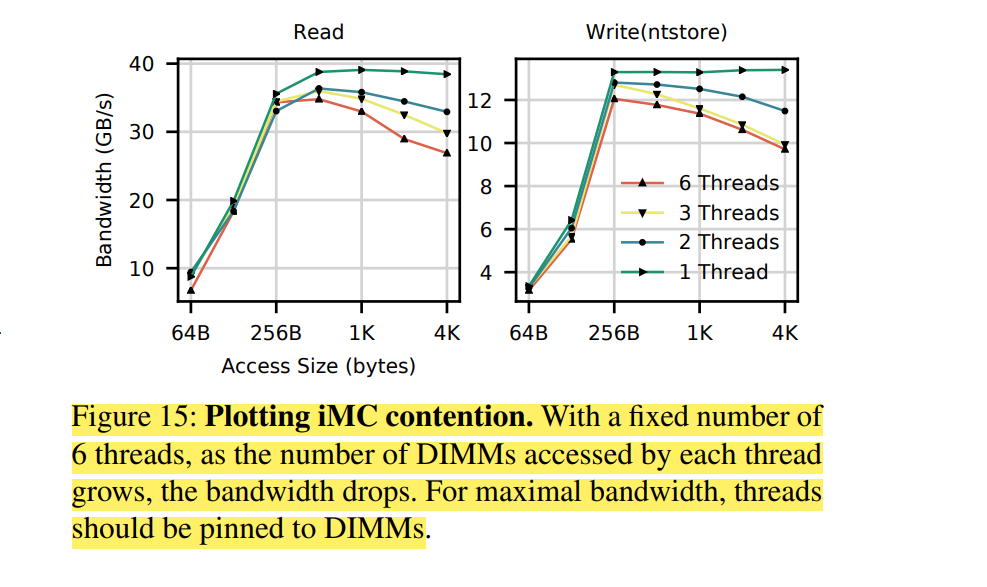
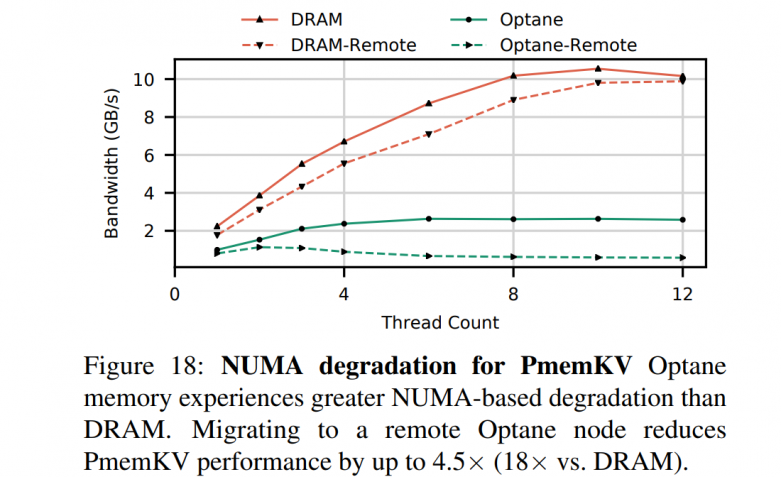
- The read latency of random Optane DC memory loads is 305 ns This latency is about 3× slower than local DRAM
- Optane DC memory latency is significantly better (2×) when accessed in a sequential pattern. This result indicates that Optane DC PMMs merge adjacent requests into a single 256 byte access
- Our six interleaved Optane DC PMMs’ maximum read bandwidth is 39.4 GB/sec, and their maximum write bandwidth is 13.9 GB/sec. This experiment utilizes our six interleaved Optane DC PMMs, so accesses are spread across the devices
- Optane DC reads scale with thread count; whereas writes do not. Optane DC memory bandwidth scales with thread count, achieving maximum throughput at 17 threads. However, four threads are enough to saturate Optane DC memory write bandwidth
- The application-level Optane DC bandwidth is affected by access size. To fully utilize the Optane DC device bandwidth, 256 byte or larger accesses are preferred
- Optane DC is more affected than DRAM by access patterns. Optane DC memory is vulnerable to workloads with mixed reads and writes
- Optane DC bandwidth is significantly higher (4×) when accessed in a sequential pattern. This result indicates that Optane DC PMMs contain access to merging logic to merge overlapping memory requests — merged, sequential, accesses do not pay the write amplification cost associated with the NVDIMM's 256 byte access size
[2]:
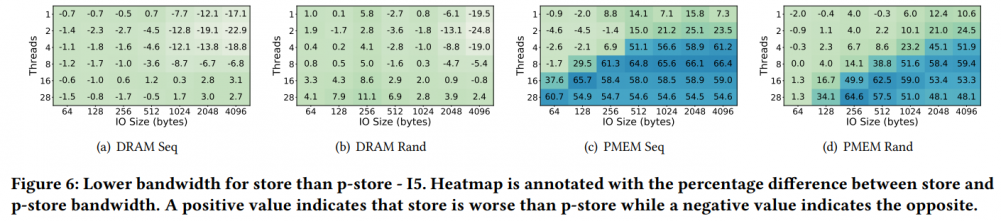
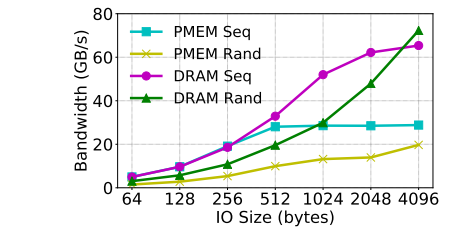
[4]:
for RDMA + PM:
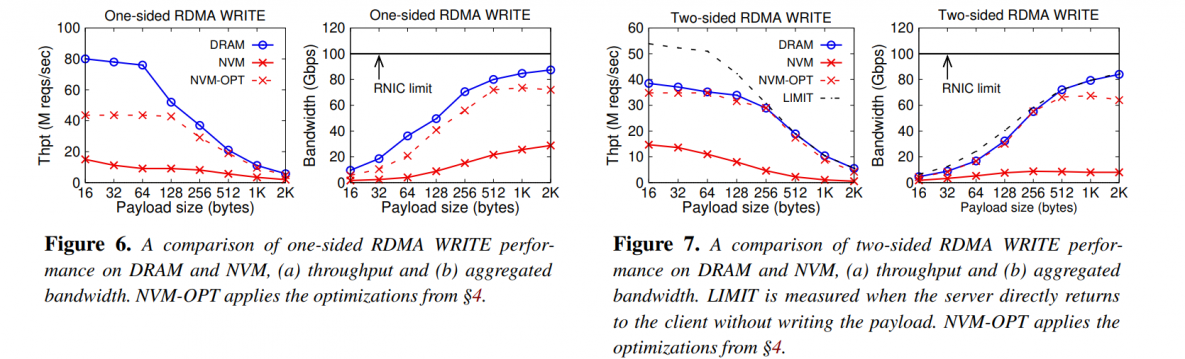
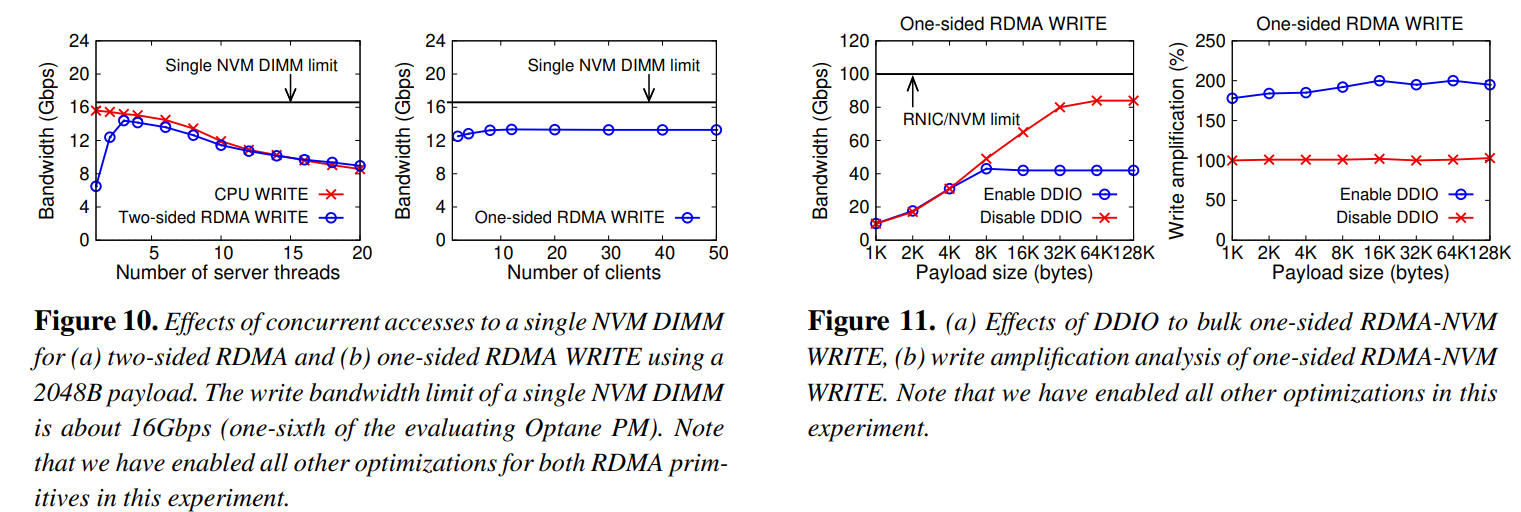

ref
- Yang, Jian, et al. "An empirical guide to the behavior and use of scalable persistent memory." 18th USENIX Conference on File and Storage Technologies (FAST 20). 2020.
- Gugnani, Shashank, Arjun Kashyap, and Xiaoyi Lu. "Understanding the idiosyncrasies of real persistent memory." Proceedings of the VLDB Endowment 14.4 (2020): 626-639.
- Wang, Zixuan, et al. "Characterizing and modeling non-volatile memory systems." 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020.
- Wei, Xingda, et al. "Characterizing and Optimizing Remote Persistent Memory with {RDMA} and {NVM}." 2021 {USENIX} Annual Technical Conference ({USENIX}{ATC} 21). 2021.
- Chen, Youmin, et al. "FlatStore: An efficient log-structured key-value storage engine for persistent memory." Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 2020.