About offloading erasure coding to NICs.
This article was written a long time ago, and the logic is a bit muddled. I recently did some new research and found this draft in Obsidian. Although a little messy, it still contains some useful information, so I polished it with a large language model and am now publishing it. (Also because I suddenly realized it's been a long time since I last updated, and procrastination before ddl.)
High-speed networks like RDMA are rapidly developing. 800 Gbps NICs are on the horizon. Despite numerous efforts dedicated to accelerating Erasure Coding (EC), EC acceleration libraries like ISA-L haven't kept pace with the advancements in networking. Consequently, for traditional EC where the bottleneck was primarily network bandwidth, a portion of the bottleneck has shifted to computation. Furthermore, computation within EC is also suitable for offloading to processors on PCI-E, which can simultaneously save CPU resources.
In fact, multi-core speed is sufficient, but yeah simple calculations should be offloaded to the DSA.
Haiyang Shi (now at ByteDance US Infrastructure System Lab), a PhD from OSU, has conducted significant research on offload encoding to NIC. his thesis
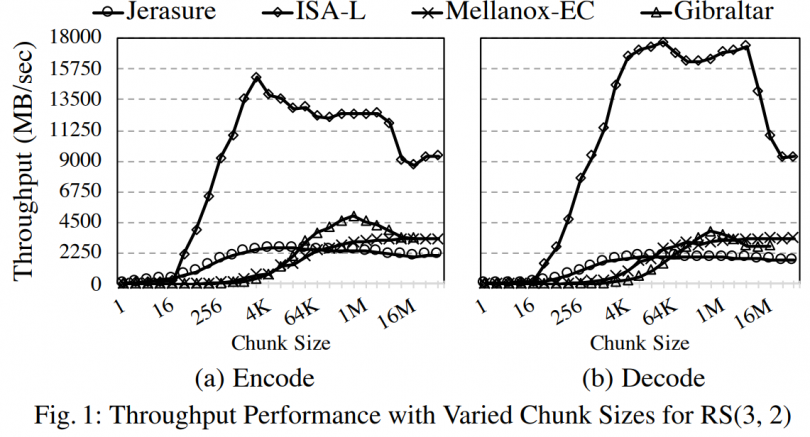 ps: Gibraltar is a EC library for GPU
ps: Gibraltar is a EC library for GPU
The figure qualitatively illustrates the current throughput performance of different acceleration libraries on various processors. ISA-L, due to its cache-friendly design, significantly outperforms others.
It's evident that while the granularity of PCI-E is 64B, the sweet spot for offload devices lies at the MB level. Therefore, for small object cases like KVS, offloading could introduce substantial latency overhead.
HPDC'19 UMR-EC: A Unified and Multi-Rail Erasure Coding Library for High-Performance Distributed Storage Systems
Goal: Integrate devices such as CPUs, GPUs, and network interface cards (i.e., multi-rail support) to execute erasure coding (EC) operations in parallel.
Methods: A unified multi-rail EC library that can fully leverage heterogeneous EC encoders. The proposed interface is complemented by asynchronous semantics, an optimized metadata-free scheme, and EC rate-aware task scheduling, enabling efficient I/O pipelines.
This work focuses on two-level hierarchies: CPU+GPU and CPU+RNIC (note: only CX5 provides EC features).
(Intuitively, disregarding implementation effort, the core focus is on managing the computing power of different devices and task distribution. Intensive multi-tasking is straightforward. For individual small tasks, such as degraded reads, how to distribute them to cores with different computing capabilities to avoid tail latency necessitates a predictor. However, this approach confines offloading to enhancing computing power rather than shortening paths, for instance.)
The primary strategy aims to reduce latency by overlapping the three stages of data retrieval, coding, and data transmission, similar to a pipeline.
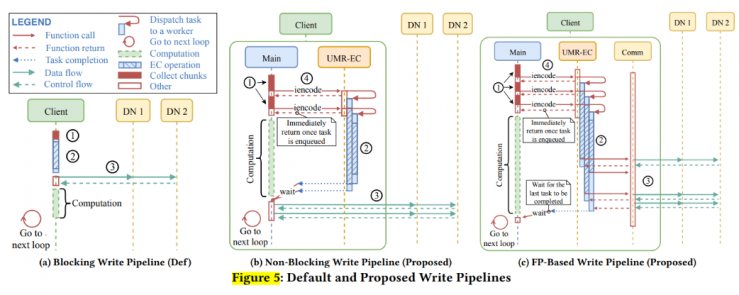
Read operations follow a similar approach. The core idea is that by splitting each coding task into multiple subtasks and distributing them across various devices, these devices can independently and concurrently complete these subtasks without blocking communication or other processes. The strategy for controlling task distribution is simple: maintaining three additional queues and observing their flow rates.
Note that although the GPU performs calculations, the CPU is still responsible for packet transmission.
seems like some data and benchmarks not align with their previous work in Bench'18?
SC'19 TriEC: An Efficient Erasure Coding NIC Offload Paradigm based on Tripartite Graph Model
This paper discusses offloading the EC computation process to RDMA NICs. The problem is abstracted into a tripartite graph model. Additionally, some network primitives are designed to support this offloading. It is primarily a networking-focused work.
Here, a key difference from the HPDC work is that the RNIC can handle network packet transmission?
Two types of offload NICs:
- Incoherent: The CPU sends data in memory to the NIC for parity calculation, and subsequently issues a command to send the parity data.
- Coherent: The NIC calculates and stores the parity data in memory before sending it.
- Benefits: Reduces CPU overhead and DMA operations (i.e., fewer read operations).
However, the above optimization strategies have limitations:
- Only one NIC is used for computation, leading to poor parallelism.
- NIC network resources are not fully utilized.
- Only the encode-and-send primitive is supported, not the receive-and-decode primitive.
Design:
- If we consider the original architecture as a bipartite graph (BiEC) (where the source and NIC are one node and the destination is another), their design is a tripartite graph. The encoding process is divided into multiple subsets and sent to multiple NICs on different nodes for calculation. This distributes the computational load across the NICs. The decoding process is similar, with decoding tasks also being decomposed and distributed. [Implementation requires designating a leader within a group to manage request distribution.]
- Finer-grained task decomposition enables improved parallelism.

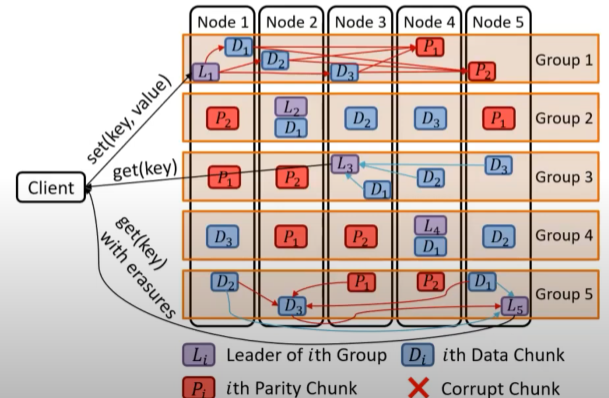
Hence, the process transforms from a single-hop to a double-hop-like network.
For in-band repair compared to out-of-band repair, intermediate results of subtasks can potentially be the desired result for a particular node without extra overhead. This allows direct delivery to that node, eliminating the need for write-back. Furthermore, the initialization overhead of the EC offload APIs supported by the NIC is significant, necessitating buffering.
It's unclear how the receive-and-decode primitive is implemented. The intermediate forwarding nodes seem to still require CPU involvement. Note that this network communication still uses two-sided verbs, not DM.
Random Thoughts
- this approach of combining subtasks to satisfy a specific node's requirements is kindof a trade-off between computation and networking?
- Furthermore, this writing strategy inherently requires writing a portion of the data to specific nodes and then having those nodes calculate parity. This is an asynchronous process. Does this compromise reliability?
- Many of the choices presented here appear to extend local encoding techniques to distributed systems. Can this be extended further?
SC'20 INEC: Fast and Coherent In-Network Erasure Coding
This work seamlessly integrates operations like receiving data, calculating erasure codes, and sending results, reducing CPU intervention.
RDMA is extended with EC primitives within network primitives, such as encode_and_send, but with further expansions like PPR for forwarding encoding types (e.g., receive_ec_send). [ec/xor-send, recv-ec/xor-send, and recv-ec/xor]
The combination of these three primitives is sufficient to express the computation and communication patterns of all five advanced erasure coding schemes shown in Figure 1.
This enables the construction of distributed erasure coding pipelines and the triggering of pre-submitted tasks without CPU intervention.

The modified Mellanox OFED driver supports INEC primitives.
The implementation uses RDMA WAIT (This seems more suitable for DPUs and Bluefield. If line rate is not achieved, it can be awkward).
refer
- Shi, Haiyang, Xiaoyi Lu, and Dhabaleswar K. Panda. "EC-Bench: Benchmarking Onload and Offload Erasure Coders on Modern Hardware Architectures." International Symposium on Benchmarking, Measuring and Optimization. Springer, Cham, 2018.
- Shi, Haiyang, et al. "High-performance multi-rail erasure coding library over modern data center architectures: early experiences." Proceedings of the ACM Symposium on Cloud Computing. 2018.
- Shi, Haiyang, et al. "UMR-EC: A unified and multi-rail erasure coding library for high-performance distributed storage systems." Proceedings of the 28th International Symposium on High-Performance Parallel and Distributed Computing. 2019.
- Shi, Haiyang, and Xiaoyi Lu. "Triec: tripartite graph based erasure coding NIC offload." Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 2019.
- Shi, Haiyang, and Xiaoyi Lu. "INEC: fast and coherent in-network erasure coding." SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020.