Prefetch to hide memory access latency (CPU stall)
- What to prefetch
- When to prefetch
- Where to place the prefetched data
Some ref:
- Prefetching、Interleaving 和 数据库
- In-Memory DBMS 『Peloton』技术简述
- 使用协程提高流水线利用率 howardlau
- https://stackoverflow.com/questions/72243997/how-to-use-software-prefetch-systematically/
note: partially translated by ChatGPT
TACO '14 When Prefetching Works, When It Doesn’t, and Why
Discussing HW prefetch and SW prefetch:
- SW prefetch is suitable for scenarios such as short arrays, sequential and irregular reads, etc. The form of SW prefetch introduces more instruction calling costs.
- HW prefetch heavily depends on the platform, as specific patterns need to be recognized.
- SW prefetch has a training effect on HW, which might negatively impact HW performance.
- HW prefetchers generally prefetch to L2 or L3, as the performance gap between L1 and L2 can be tolerable for an OOO CPU when the miss rate is below 20%.
For more details on this topic, refer to: https://hackmd.io/@jserv/HJtfT3icx?type=view
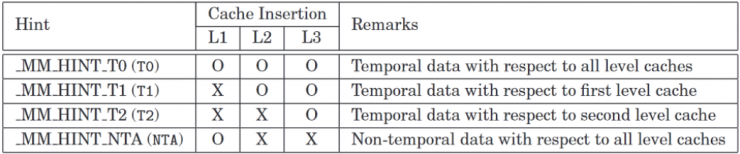
- T0 (Temporal data) - Prefetch data into all levels of the cache hierarchy.
- T1 (Data about L1 cache misses) - Prefetch data into level 2 cache and higher levels.
- T2 (Data about L2 cache misses) - Prefetch data into level 3 cache and higher levels, or as implementation-specific choices.
- NTA (Non-Temporal data across all cache levels) - Prefetch data into non-temporal cache structures and prefetch it to locations close to the processor, minimizing cache pollution.
prefetchntais only used to prefetch into the USWC memory region using line fill buffers. Otherwise, it prefetches into L1 (and L3 inclusive L3 on CPU), bypassing L2 (as stated in Intel's optimization manual). You cannot weakly order loads from WB memory; there is no way to bypass cache coherence on WB.
For further insights, refer to: https://stackoverflow.com/questions/46521694/what-are-mm-prefetch-locality-hints
BUT
For databases, workloads such as point chasing are prevalent, as seen in hash joins, where HW prefetching is ineffective.
- Hash join involves a large set of keys, and the task is to perform table lookups [used in table joins for two DBs, resulting in a significant amount of random memory access].
- MVVC chains are another example.
- However, integrating operations other than hash join into this context is certainly challenging, and it might require a case-by-case approach.
While some works might only discuss hash joins, the ideas are generally applicable, so distinctions regarding whether the implementations in the articles are general are not considered here.
ICDE '04 Improving hash join performance through prefetching
Sw prefetch for hash join. In comparison to simple SW prefetch, which prefetches all related pages before access, further proposals include Group Prefetching and Pipelined Prefetching.
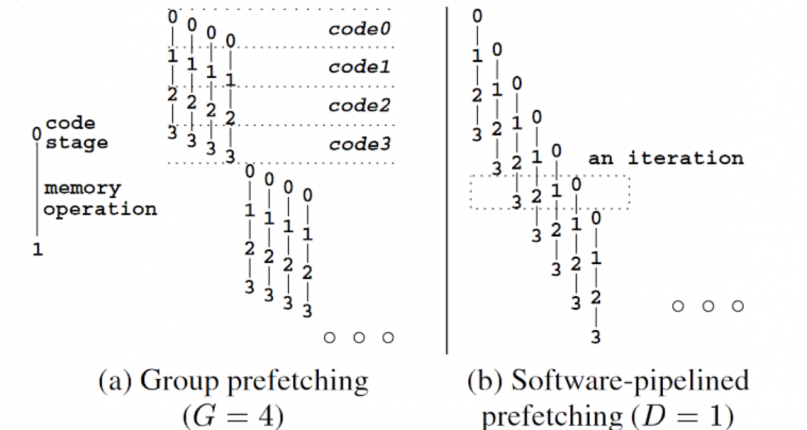
The idea is straightforward: for a batch of tasks, prefetch first, then perform subsequent computations. By the time the data is retrieved, it is already in the cache. Pipelined prefetching goes a step further than group prefetching, which naturally imposes additional constraints on the size within each loop body, batch size, and so on.
https://ieeexplore.ieee.org/document/1319989
https://zhuanlan.zhihu.com/p/443829741
VLDB '17 Relaxed Operator Fusion for In-Memory Databases: Making Compilation, Vectorization, and Prefetching Work Together At Last is an example of a DB using GP (with SIMD). There are more detailed experiments, but it seems there are no significant changes in terms of methodology (although this isn't the focus of this article).
https://zhuanlan.zhihu.com/p/51588155
VLDB '16 Asynchronous Memory Access Chaining
AMAC provides a method to transform the pattern of chaining access (point chasing with many pointer dereferences) into one that can be SW prefetched in coding, but this requires a significant amount of manual effort, even for probing a hashtable.
The key observation is that not every access chain has a fixed size. Therefore, theoretically ideal pipeline prefetching isn't practical, and there will always be instances of pipeline stalls in irregular scenarios, similar to what occurs in superscalar processors.
Thus, they utilize a Finite State Machine (FSM) to abstract the entire process, enabling early modifications in the code to fill the pipeline effectively.
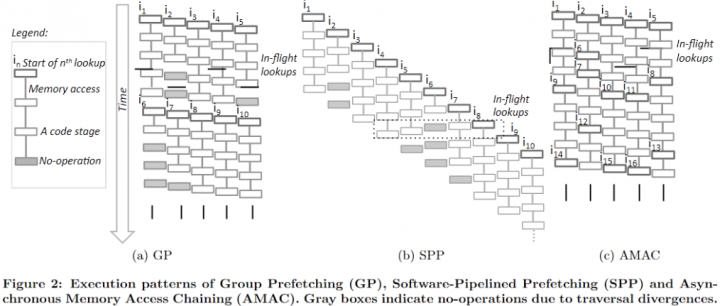
In comparison to simple group or simple pipeline strategies, AMAC represents a more dynamic approach, accounting for different sizes, among other factors. It emphasizes observing the dependency relationship to interleave prefetch and computation.
Interestingly, even if you handwrite the state machine, the compiler might still mess up your code, making it slower. Watch this video for more information.
VLDB '17 Interleaving with Coroutines: A Practical Approach for Robust Index Joins
AMAC is excellent and can approach the theoretical limit indefinitely, but it is not practical. This work proposes using coroutine switching to replace manually interleaved execution. It delegates the task of scheduling interleaving to the compiler or DB engine.
The advantage of coroutines lies in their low switching overhead. Unlike heavyweight threads, in the best-case scenario, the overhead can be almost equivalent to that of a single function call.

Significantly, SW prefetching is indeed sensitive to many aspects, and such interleaving can potentially impose greater pressure on address translation. The group size still needs manual adjustment.
Note that here, of course, coding still needs to be done in this pattern, and engine developers still need to manually adjust various details of coroutines.
VLDB '18 Exploiting coroutines to attack the "killer nanoseconds"
The discussion also revolves around using coroutines in DB to reduce memory stalls in pointer-intensive data structures. They transformed hashtables, binary searches, and more complex data structures like masstree and bw-tree, conducting numerous tests.
There are many intricacies, but only a few minor details are listed here:
- HW thread (referring to Hyper-Threading) prefetch is not as effective as coroutine prefetch (referenced in eurosys22).
- The performance of coroutines varies significantly among different compilers.
- …
There is also a connection to the line fill buffer (since the line fill buffer is also used for non-temporal store and similar operations, it appears that there might be some competition in this context).
VLDB '20 Interleaved Multi-Vectorizing
This is the work of ECNU by Zhuhe Fang, Beilei Zheng, and Chuliang Weng. It is also about SIMD+SW prefetch, which is quite an interesting study.
- The first issue pertains to SIMD, which requires multiple contiguous data but might not all be present in the cache, resulting in a direct slowdown.
- An interesting experiment demonstrated that although SIMD is often claimed to be powerful, its performance rapidly degrades as the workload size increases, becoming similar to scalar operations. Cache misses take around 200 cycles, which is orders of magnitude higher than the computation cycles. [ Does dense SIMD also lead to frequency reduction? ]
- The second issue concerns the possibility of empty registers within SIMD, where some parts of the code stage might not be fully utilized, leading to a problem of underutilized hardware resources.
They proposed IMV:
- (Manually) interleave the execution of different SIMD computations to implement SW prefetching and reduce cache misses.
- Introduced residual vector states to merge with divergent vector states.
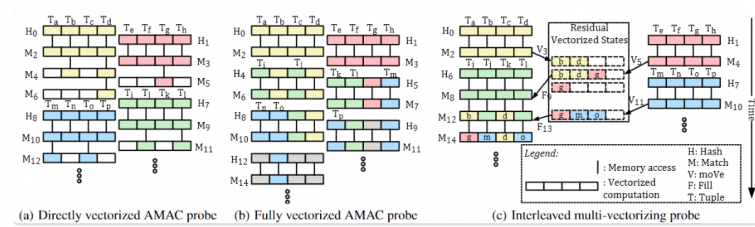
Understanding the concept is straightforward from the diagram.
*it seems that at least one assumption here is that misalignment exists? If alignment is directly addressed, all cache misses or code situations would be fully aligned in 64B units, leading to complete consistency.
Experimental results:
We compared the performance of IMV with various other methods on Hash join probe (HJP) and Binary tree search (BTS). As shown in Figure 6, in most cases, IMV outperforms other methods, being 2.38 times, 1.39 times, 2.22 times, 2.74 times, and 4.85 times faster than AMAC (scalar code interleaving), FVA (fully vectorized AMAC), RAV (direct vectorized AMAC), SIMD (direct SIMD coding), and Naive (basic scalar implementation), respectively. In this experiment, Intel Vtune was used to further analyze the advantages of IMV through microarchitectural indicators, and the time breakdown of its execution is shown in Figure 7. The figure explains why IMV is much faster than other methods. IMV not only reduces maemory access overhead but also eliminates speculative execution errors. The results from Naive (pure scalar implementation) indicate that the execution time of HJP and BTS is mainly spent on memory access. Although AMAC optimizes memory access to improve performance, it is severely limited by speculative execution errors. Compared to Naive and AMAC, SIMD on the CPU only eliminates branch errors with little effect, as there are a large number of cache misses.
Link to Zhihu Link to Bilibili
VLDB '21 CoroBase: coroutine-oriented main-memory database engine
Continuing from the previous work, this study also adopts a strategy of using alternating coroutines to implement SW prefetch. They aimed to create an implementation that is as automated as possible, which led them to explore C++20 coroutine. (Note that C++20's coroutine is stackless compared to boost, using suspension for switching.)
It's essential to note that the granularity here does not involve multiple threads as a batch, but rather multiple get() operations. This distinction sets it apart from AMAC, showing better performance with a small number of threads.
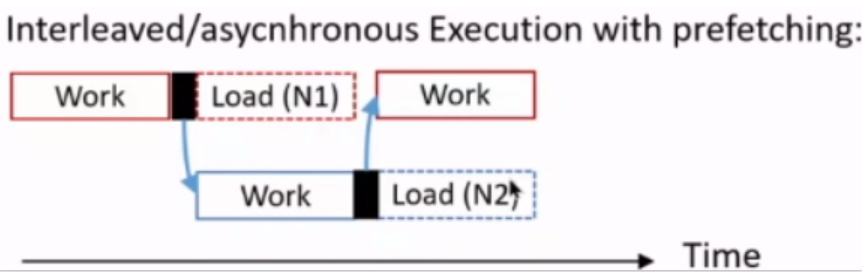
The major problems they encountered were as follows:
- Coroutine switching overhead: The overhead is significant every time there is a suspend, so they implemented a two-level system. However, some parts still require manual unwinding.
- Scheduling: Fixed batch size based on profiling, such as the optimal number of CPU hardware prefetches, constrained by the number of registers, and so on.
- Resource management: Adjusting the timing of resource entry and reclamation.
- Concurrency control and DB architecture choices: Thread-local transformation.
A drawback of reducing the execution granularity is that the overhead of synchronization locks increases.
Tianzheng Wang's presentation can be found here: Bilibili Link