RDMA+KVS. Different with local hashing, insertion, deletion and update are expensive in RDMA environments. So a carefully index design based on one-sided RDMA ops is crucial.
background
some related works: (you can check [1])
- RDMA indexes
- Palif uses Cuckoo Hashing, which will use a large number of RDMA CASes and WRITEs to deliver a insertion.
note: RDMA CAS (8B) is super slow
- FaRM uses Hopscotch Hashing (a variant of linear probing), which also brings expensive locking ops.
- DrTM use Cluster Hashing (a variant of collision chaining). Traversing chain buckets is so much consuming.
- Palif uses Cuckoo Hashing, which will use a large number of RDMA CASes and WRITEs to deliver a insertion.
They all suffer something from too many RDMA ops.
- hash table resize
- CCEH use sub-tables to optimize table resizing. But sub-table flags will cause another RTT. Further, using cache for sub-table will introduce inconsistency.
contribution:
- an RDMA-conscious (RAC) hash subtable structure
- a lock-free remote concurrency control scheme
- a client directory cache with stale reads scheme
an RDMA-conscious (RAC) hash subtable structure
hash table design combined some popular tricks.
- associativity
- one bucket for K slots, just like FaRM
but FaRM isn't refered here..
- one bucket for K slots, just like FaRM
- use two choice method to select a low load bucket
refer to the power of two choice.
- set a overflow bucket between 2 buckets
- a discrete overflow bucket will introduce another RDMA read.
question: this design refers to level hashing, but what if compare it to an allocation with a bigger space (x1.5)?
- a discrete overflow bucket will introduce another RDMA read.
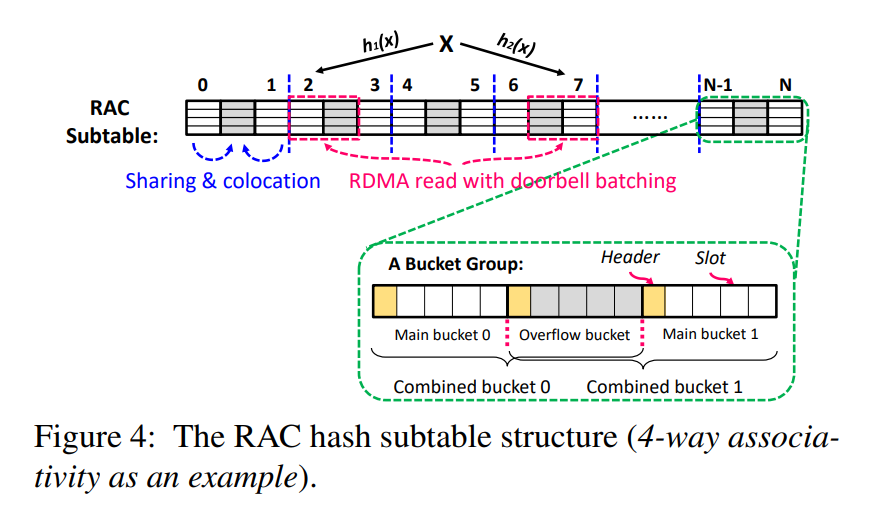
the bucket in grey color is the sharing colocation bucket.
a lock-free remote concurrency control scheme
structure:
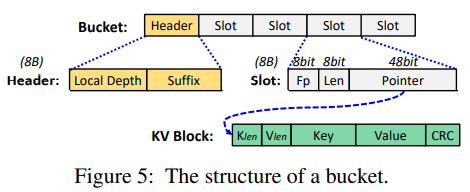
- lock-free insert
- use doorbell batching to read 2 combined buckets based on the given key. Parallelly, write data to memory pool (table only stores pointers)
- search a empty slot and use RDMA CAS to write this slot.
- since contention may lead to duplicate writes to 2 buckets, we have to read these two buckets to check for any duplicate keys.
so another RDMA CAS…
- lock-free deletion
- find slot
- RDMA CAS set null
- set data block zero
they claim that zero-setting is for security. can't get it, they should be orthogonal…
- lock-free update: …
- lock-free search: read -> check fp -> read -> check full keys -> check CRC
remote resizing
Problem: clients use sub-table caches to save extra RTTs, while invalid caches after resizing will lead to invalid data block. Plus, blocking ops while resizing is expensive.
So they use headers of buckets (local depth & suffix bits) to verify that it's stale. details in paper…
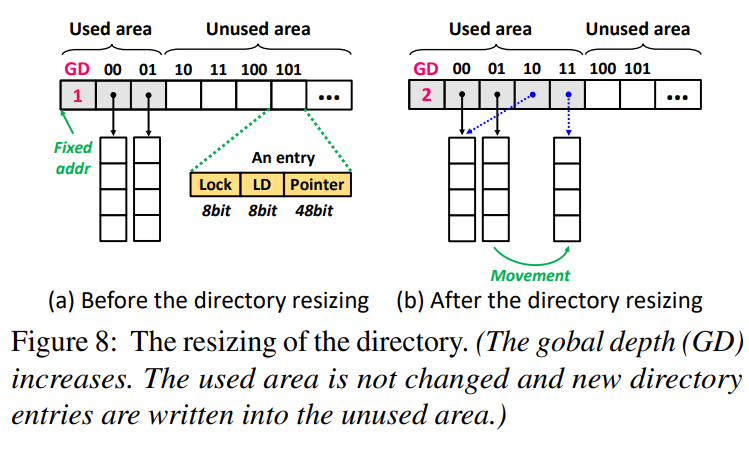
for concurrent resizing, they pre-allocate a unused area next to used area (ordinary area).
To resize the directory, e.g., increasing the GD from 1 to 2, the used area is not changed and the new directory entries are written into the unused area. So that all ops except resizing will not be blocked.
experiments
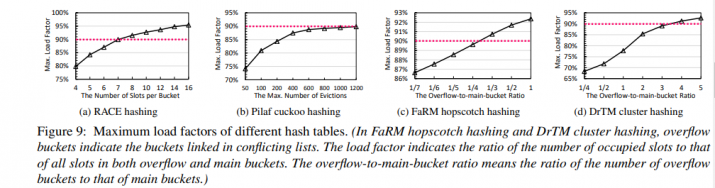
…
refer
- https://www.grayxu.cn/2020/11/10/RDMA+KVS/
- Mitzenmacher M. The power of two choices in randomized load balancing[J]. IEEE Transactions on Parallel and Distributed Systems, 2001, 12(10): 1094-1104.