RocksDB based on LSM-Tree is widely used in Facebook. This work aims to model and analysis RocksDB workloads at Facebook.
Use Case
- UDB, storing social graph data.
- MyRocks uses RocksDB instead of InnoDB of MySQL. Since RocksDB doesn't support structured data, key and value would be organized as structured. And the composition schema is different:

Seems like a strong key pattern here..
- MyRocks uses RocksDB instead of InnoDB of MySQL. Since RocksDB doesn't support structured data, key and value would be organized as structured. And the composition schema is different:
- ZippyDB, a distributed RocksDB based on Paxos.
- In this case, key is usually the name of objects and value is used to be pointers.
- UP2X to store user profile data and support ML/DL.
- It contains lots of statics information, as a result, lots of writes on UP2X.
Requests composition
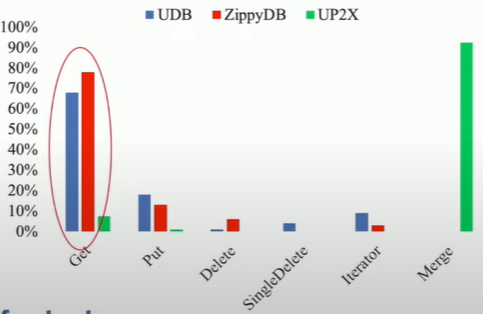
for UDB and ZippyDB, GET requests dominates.
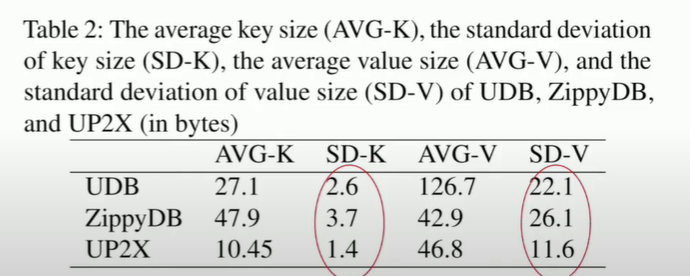 the standard deviation of key is relatively small while the deviation of value is large!
the standard deviation of key is relatively small while the deviation of value is large!
And values in UDB is larger than others about 3 times. (because Posts is big like a image or something
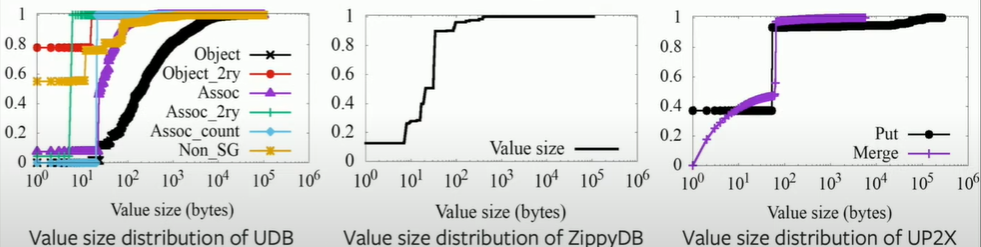
Key & value size distribution
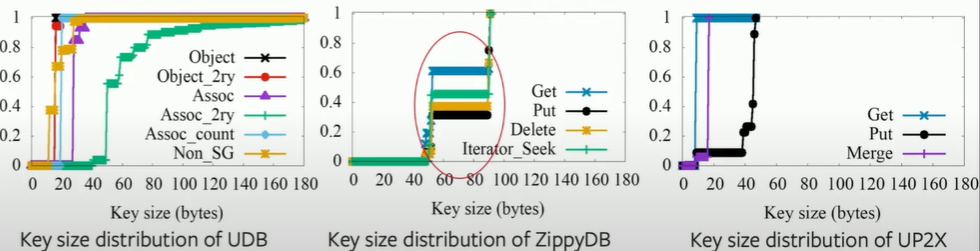
In ZippyDB, most of data is around 50 bytes or 90 bytes. Similar in UP2X, the key size is around 10 bytes.
But when it comes to UDB, some are fixed around 10~20 bytes, while some related to the association's secondary index can be very large (>100bytes)! Since we need to use those information to do iterate
Same with previous works, they find QPS have a strong diurnal pattern.
Access distribution

less than 5% of data are accessed during 24 hours. in other words, most of data are cold.
In UDB, 70% of data are write once without any update.
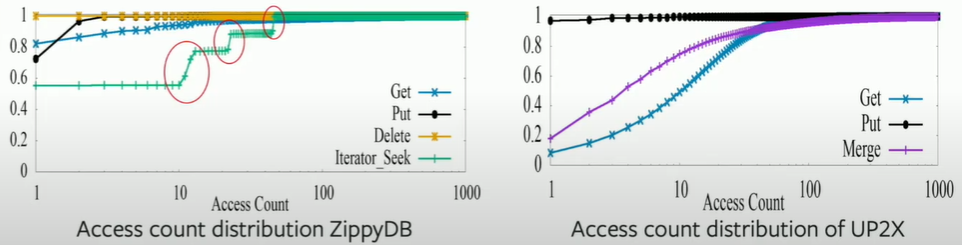
the stair in ZippyDB's graph reveals that some of keys are often repeatedly selected as the start key to do iterate.
have a small hotspot here?
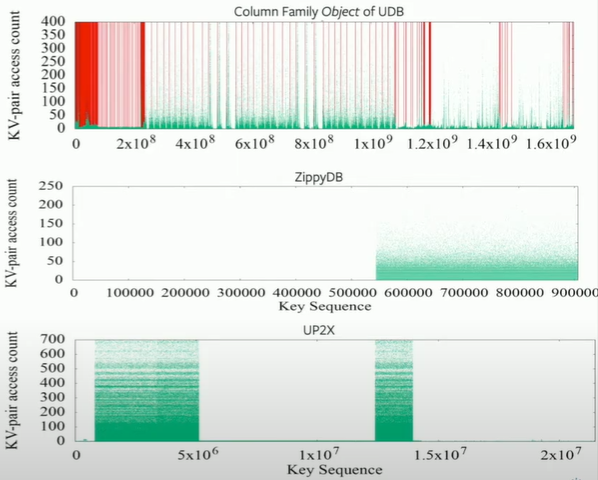
access distribution is related to key distribution! -> key space locality!
Also, for some query types, temporal locality is clear.
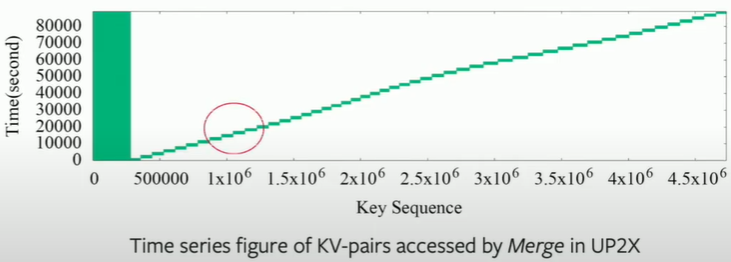
Difference with YCSB
Workloads generated by YCSB will lead to smaller write amplification and more reads compared with real workloads.
(because rocksDB is build upon a filesystem, those static data are collected on file system level)
The reason is hot keys is randomly put in key-space. This uniform distribution will cause more cache replacements, aka more reads.
How to deal with it?
Instead of only modeling the overall space, they cut space into pieces. In each piece, workloads follow the uniform distribution, while keep locality on the piece level.

it doesn't make sense… since the logical, semantic distance is not key-address distance. Through it may cause similar read and write ratio on file system level, it's still not REAL.
especially for structured key like in UDB
And based on this design, they bring some new benchmarks.
All tools and benchmarks are open sourced on Github.
👍
refer
- Cao, Zhichao, et al. "Characterizing, modeling, and benchmarking rocksdb key-value workloads at facebook." 18th {USENIX} Conference on File and Storage Technologies ({FAST} 20). 2020.