This work points out that how to utilize low-level performance of a hierarchical storage system.
Motivation: The differences between today’s neighboring storage layers are less clear and even overlapping (depending on workloads)
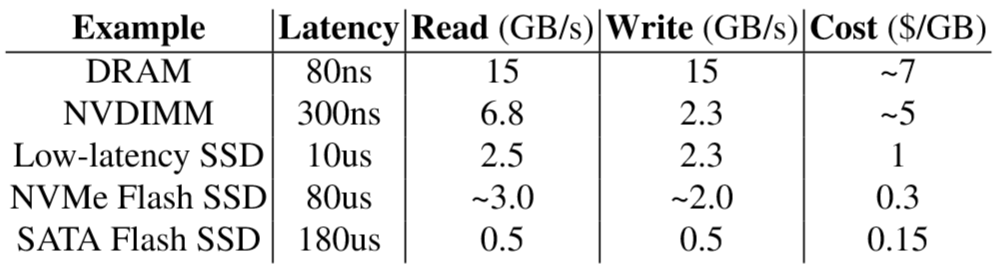
Usually, in hybrid storage system, there would be two or more layers including performance devices and capacity devices. The former is small but fast, and the latter is big and cheap but slow. However after new storage devices come to world, like Optane and NVMe SSD, the border among layers are becoming blind: low-level devices can achieve similar performance with higher ones on some workloads.
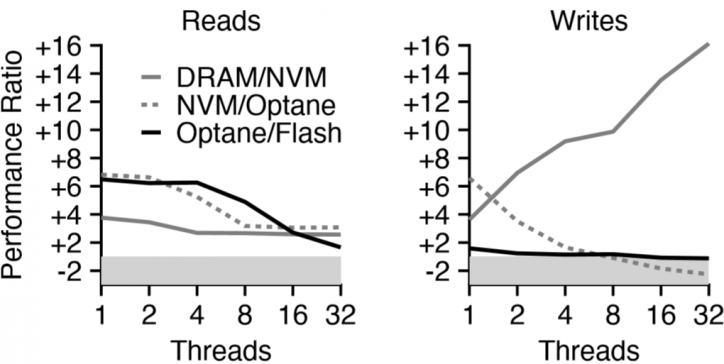
Especially when the high level devices is saturated and over utilized, cache hit rate would be affected a lot. And the whole system's performance would be limited by the highest level.
So as a result, their optimized design NHC cache controller will dynamically offload some requests to low levels to utilize lower level performance while not lossing fast caching performance.
question:
send requests to lower level would lead to tail latency problem?
related work: LBICA [DATE '19] offload some read requests from SSD to HDD…
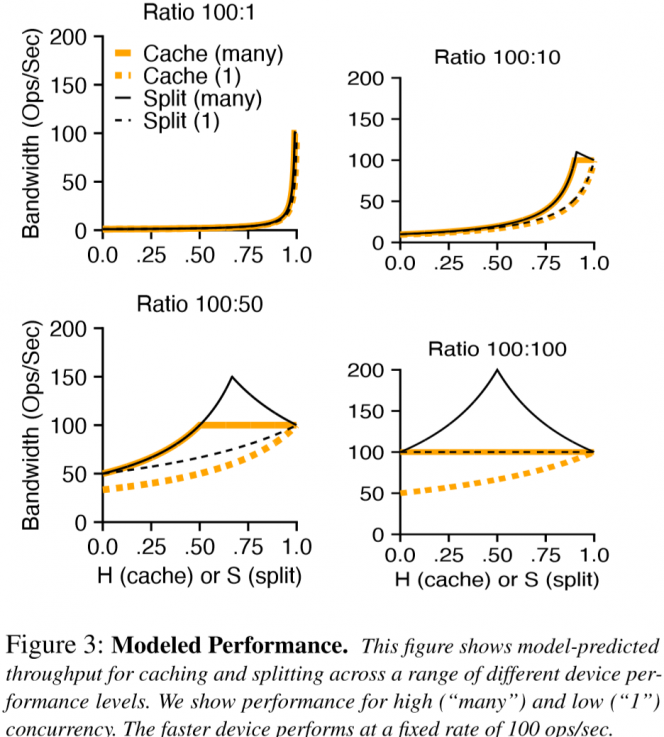
As the figure shows above, the bigger performance gap between splitting (split requests to appropriate level ideally) and caching, the smaller two level devices' performance gap.
lots of experiments as a part of motivation is redundant here? since we can raise an extreme example that we split DRAM into 2 pieces, one for cache and one for storage. And of course the performance would degrade…
So the increasing of hit rates of cache system can't bring extra throughput if the cache devices reach their maximum performance. While the misses will lead to unnecessary data movement at the same time.
archi
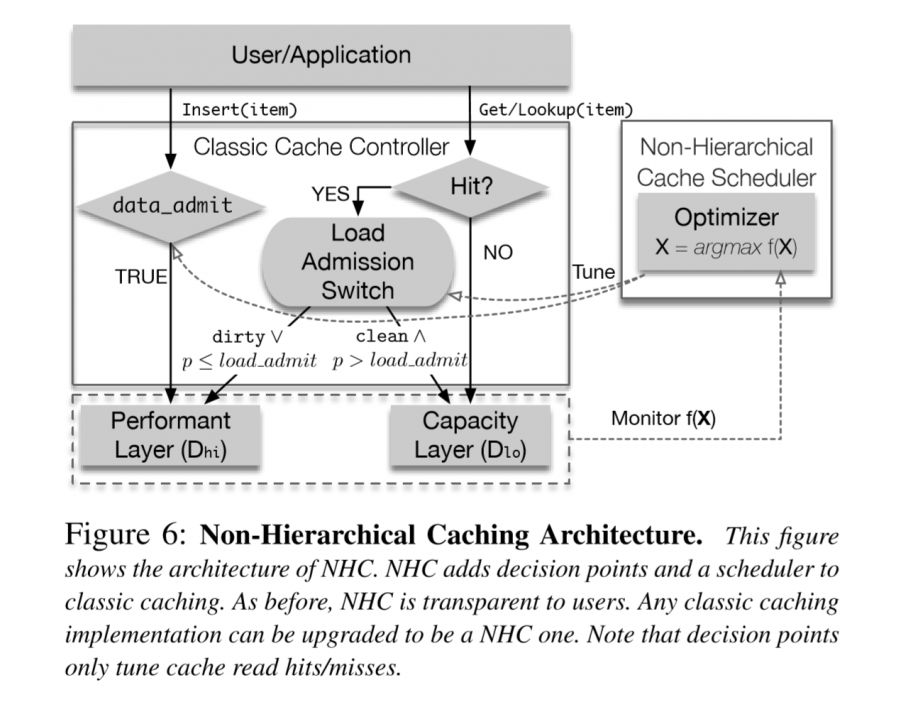
- When cache system is warming up, NHC scheduler would perform classic caching scheme (like LRU…) to make sure NHC will perform as well or better than classic caching. NHC will end this phase when the hit rate is stable and the performance is near peak.
- After high level is stable, NHC scheduler will adjust load between devices to increase low level's performance while not decreasing high level's. The threshold here is adaptively changing according to performance. Data selection is random sampling.
Only one parameter, the splitting ratio, will be tuned.
This paper use a number of terms to indicate detailed algorithm, which makes whole some parts look like source codes… Seems like it's unnecessary?
implementation
they implement Orthus-KV based on WiscKey.
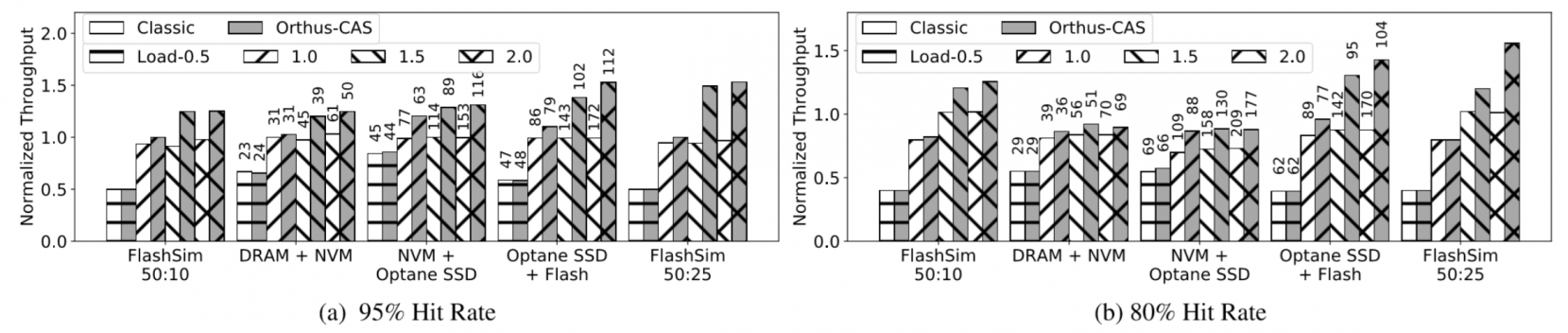
old caching strategies are limited by high level's performance
average latency is reduced by up to 42%.
extra CPU overhead:0~2%
Using ZippyDB benchmarks as dynamic workloads
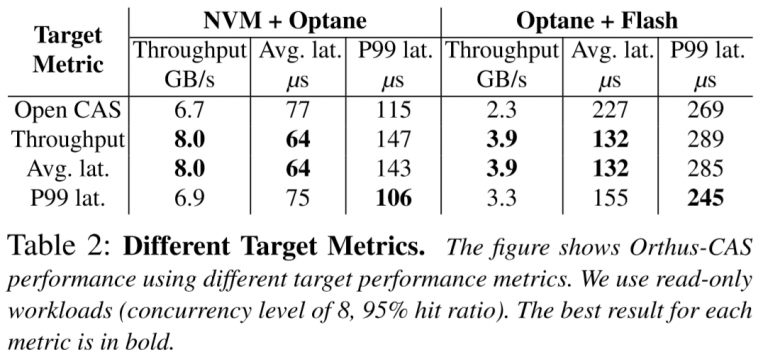
the performance metrics are chosen manually. Throughput and average latency are easier to increase here.
this figure is interesting… Some weakness behind tail latency?
refer
- Wu, Kan, et al. "The Storage Hierarchy is Not a Hierarchy: Optimizing Caching on Modern Storage Devices with Orthus." 19th {USENIX} Conference on File and Storage Technologies ({FAST} 21). 2021.