This work focuses on the bottleneck of file-mapping in NVM filesystems.
The "file mapping" here aims the translation and allocation from logical address (inode-num, logical block) to physical address in I/O path. They claim that file mapping comprise up to 70% of all overhead.
related works: strata, ZoFS, NOVA, SplitFS…
Their works:
- analyze file mapping in PM
- lots of experiments in this part, including page cache, size, space utilization, fragmentation…
- Also legacy structures suffered perf loss on large files and update ops.
This part contains lots of details!
- optimize file mapping structures
- cuckoo hashing
- …
- HashFS
- use hash table with linear probing to index file data. and the file offset is the hashing collision offset.
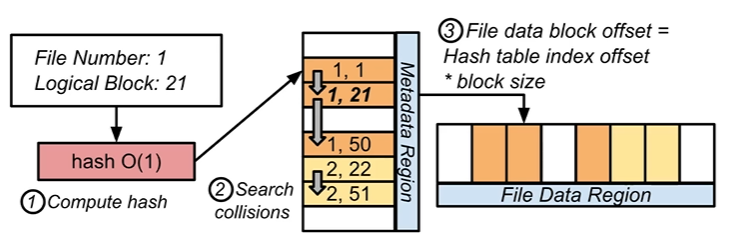
- intuition behind this design: since page cache is harmful, hash table can make sparse and random update operations efficient. As a result, it also saves cost of block allocator management.
- the implementation is only depend on memory primitives
- To avoid resize hash table, statically allocate a super big global table.
or can we use multiple tables?
- Use SIMD to accelerate I/O for lookup, since lookup can be done in parallel.
- use hash table with linear probing to index file data. and the file offset is the hashing collision offset.
- cuckoo hashing
- evaluate them on real workloads
- YCSB: 10-45% gains
- filebench: …
- locality:
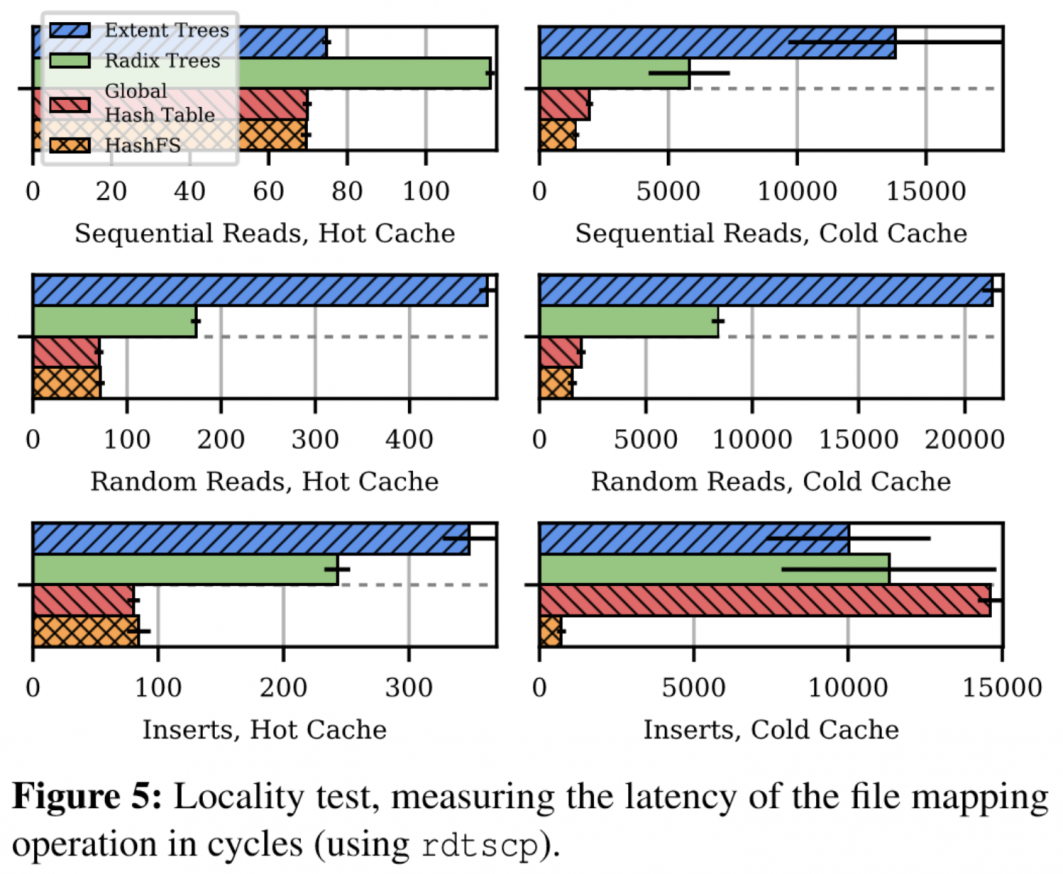 > ???
> ???
A good work lead by findings of experiments.
refer
- Neal, Ian, et al. "Rethinking File Mapping for Persistent Memory." 19th {USENIX} Conference on File and Storage Technologies ({FAST} 21). 2021.