paper notes about XStore[1] from SJTU, which uses learned cache (aka learned index[2]) for distributed DRAM KVS.
backgroud
- 7 RTT for 100M KVS with tree index -> slow
- big index tables do bad to caching
- high miss rate
- cost clients' mem
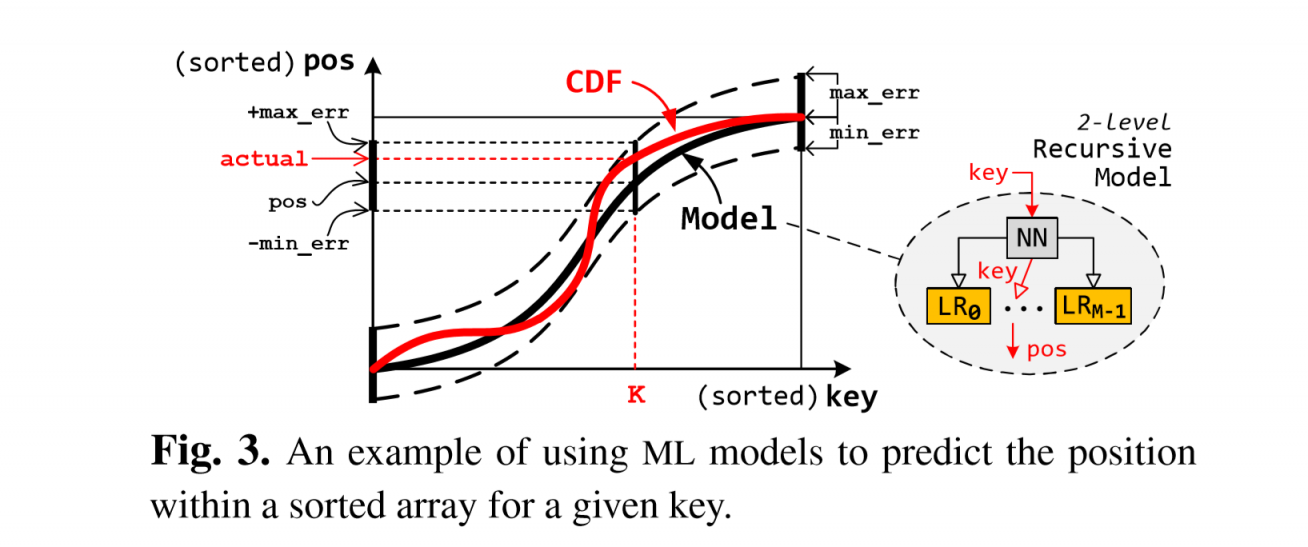
learned index: a machine learning approach to approximate the cumulative distribution function (CDF) of the keys in the tree index, which save searching cost in tree index and parameters storage cost.
XStore
process:
- update, insert…: server centric -> two-side RPC
- get: client centric -> O(1) with learned cache
learned cache:
- like learned index
- index traversal -> cal
- smaller index model than index tree, which is good for client caching
learned index works for a sorted & static array. (range query)
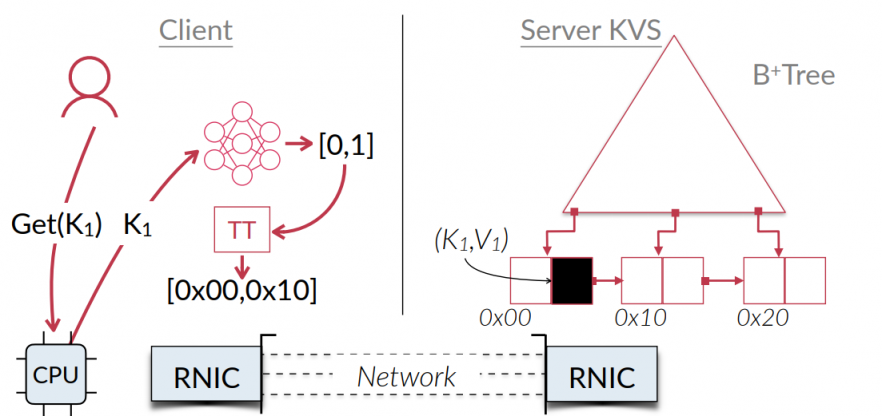
GET steps:
- key => model => a guaranteed space (value addr)
- clients fetch all keys in this space, and get the true key.
- another READ for the corresponding value
benefits:
- 1 RTT for lookup
- small memory cost
BUT index trees are not static!
server side
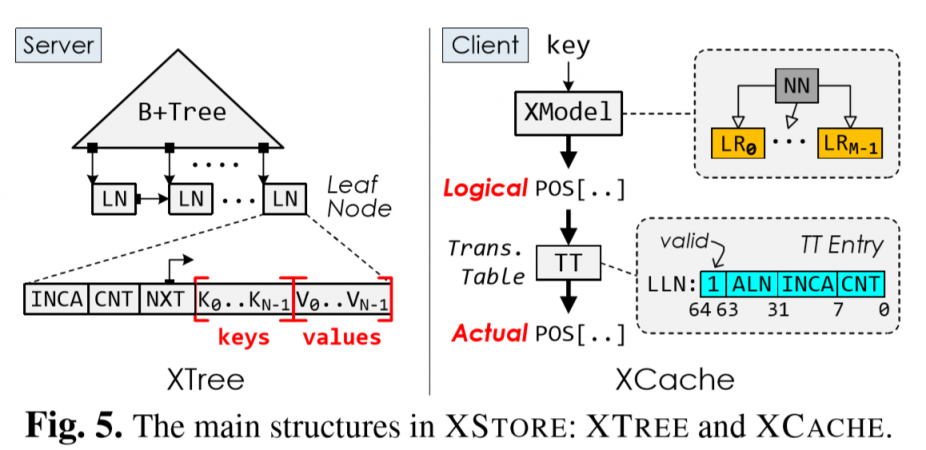
server side maintain a hybrid structure: B+Tree + Model
- virtual leaf nodes for insert
- key&value are stored seperately but continuously. Read value by offset from its key
- logical addr in leaf nodes are not sorted (just sorted logically)
- a 2 level XModel (NN+LR) predicts a position sorted range from a key.
- insertion make array unsorted: a translation table(TT) maps logical addr to the phsical, which would be cached partially in clients
- model use RMI[2] to reduce re-train costs.
model
- top level assign keys to sub-models
- sub-models predict positions with min& max error. A sub-model owns a TT and a logical space.
- due to small sub-model size and simplicity(LR), training is fast
- 8μs for retraining
- 8s for training the entrie cache
Index Tree
XTree use an HTM-based concurrent B+tree[3][4] to ensure atomicity with high perf
I konw little about HTM, so u better go to read 5.3 in the paper…
UPDATE:
- traverse XTree, and update value inplace. so it will not change index.
- optimaztion: update msgs carry position predicted by client's learned cache to reduce server's load
INSERT & DELETE:
- normal B+tree moves kv pairs to keep them sorted.
- XTree doesn't keep it within a leaf node. Since READ would read a whole leaf node, it won't effect READ.
- set flags and rewrite data for DELETE to avoid changing index
- when node split, increment incarnation (kind of some flags to indicate inconsistency), and retrain model
Based ops above, a stale TT can still maps correctly as long as accesses are not overlapped with split nodes.
Optimization trick:
- speculative execution. Clients can try to read data from stale TT entry, since half of old data still reside in this node. If miss, then read data from right-link. Good for insert-dominated workloads.
- Model expansion from XIndex[5] to handle growing kvs size.
scale out
refer to [6]. Also need to use boundary key augmentation.
Clients keep one learned cache for each server. Use a particularly partitioning func to choose server.
When a SCAN across many servers:
- collecting nodes across different servers, serially?
- one RDMA_READ for each server
read can also use that partitioning func? i don't get it
client side
clients need to cache 2 components
- model
- the table (most of space)
Operation:
- GET
- use XModel to predict a position range (mostly a single leaf node with $N$ slots)
- get real addr by TT
- read keys by one RDMA_READ with RDMA doorbell batching
- scan and identify keys is valid or existent, then read value by another RDMA_READ.
- if keys or TT entries are invalid, start to update local model and TT
- Scan
- look up related leaf nodes to determine the remote address
- read related leaf nodes with both keys and values by RDMA_READ
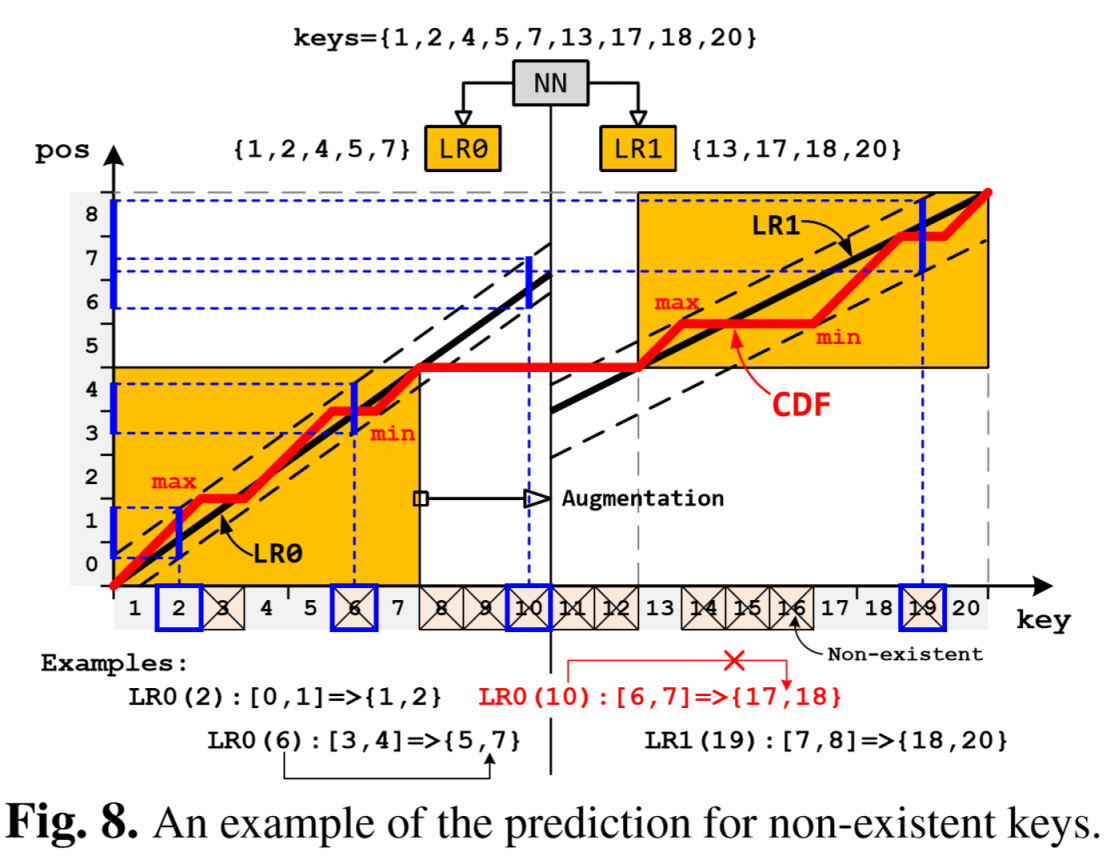
learned index use monotonic models to identify existence.
So non-existent keys would cause some problems:
model can't predict untrained area. e.g LR0 can't handle LR0(10)
solution: "data augmentation":
train models with a boundary key, so model can predict correct boundary. e.g. LR1(19)=>(18,20)
not the typical data augmentation….
eval
- model size: 500K LR(14B*500K)
- senstive to workload's pattern (complex↑ -> ↓)
- compared with tree-index caching, cache size 600MB->150MB
- if use 1% cache size -> only 20% perf loss
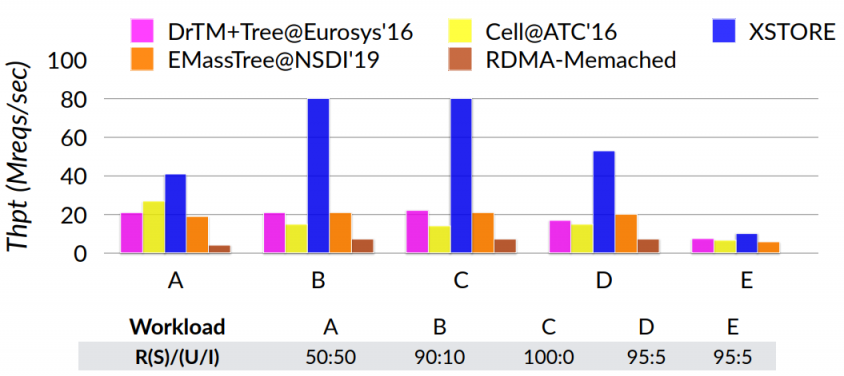
benefits from no server CPU bottleneck and reduced network cost. Bigger advantage when uniform workloads (hot data is easy to cache, and the real workload..
limitation
- fixed key-lens
- use hash to encode variable-length keys
just like fatcache
- use hash to encode variable-length keys
- model selection: LR is not so good, though good for retraining
- complex data distribution
just trade off between acc&cost
- complex data distribution
refer
- Wei, Xingda, Rong Chen, and Haibo Chen. "Fast RDMA-based Ordered Key-Value Store using Remote Learned Cache." 14th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 20). 2020.
- Kraska, Tim, et al. "The case for learned index structures." Proceedings of the 2018 International Conference on Management of Data. 2018.
- Wang, Zhaoguo, et al. "Using restricted transactional memory to build a scalable in-memory database." Proceedings of the Ninth European Conference on Computer Systems. 2014.
- 硬件事务内存(Hardware Transactional Memory, HTM)
硬件事务内存系统一般是在每个处理器核心中增加事务cache,同时在CPU指令集中增加事务相关的指令。在执行事务的过程中,事务访问过的数据会缓存在事务cache中,修改过的cache一致性协议会检测各事务之间的冲突。如果产生冲突,对应的事务cache中修改过的数据全部作废,该事务重新执行;如果没有冲突产生,就在事务结束时把事务cache中的数据更新到内存中。
硬件事务内存系统完全由硬件电路实现,所以其性能相较于软件事务内存系统有很大的优势,但是由于硬件资源的限制,所以硬件事务内存无法处理大型事务(在处理大事务的过程中会产生大量的共享数据修改操作,这些修改记录的大小超过处理器内事务cache的大小)。为了保证事务的完全执行,现有的商用硬件事务内存系统会加入串行部分,也就是“锁”,对于一部分硬件事务内存实在无法完成的事务就用串行部分完成,这虽然损失了部分性能,但至少保证了功能的完整性。
在具体实现时有2个要点: 1. 使用处理器内部的事务cache来存放事务执行过程中更新的数据,这一类的经典代表:TCC 2. 使用cache一致性协议来检测事务之间共享数据访问的冲突,这一类的经典代表:LogTM.
from https://zhuanlan.zhihu.com/p/151425608 - Tang, Chuzhe, et al. "XIndex: a scalable learned index for multicore data storage." Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 2020.
- Ziegler, Tobias, et al. "Designing distributed tree-based index structures for fast RDMA-capable networks." Proceedings of the 2019 International Conference on Management of Data. 2019.