paper notes about Persimmon[1] from UCB & MSR uses state machine scheme to utilize PM to add persistence to in-mem storage systems
background
Challenge:
- Move DRAM system directly can't bring crash consistency (all or nothing)
here the crash consistency is like transaction.
- normal approach is logging
- complex codes and high overhead
Persimmon
overview
Key insight: in-mem storage system is a state machine
- encapsulate state
- atomic operations
So state machines can be PM abstraction.
Persimmon keeps 2 copies of state machine in DRAM and PM.
op logging for crash consistency
- fast and 1 seq write to PM
- replay on the PM state machine (aka "shadow execution")
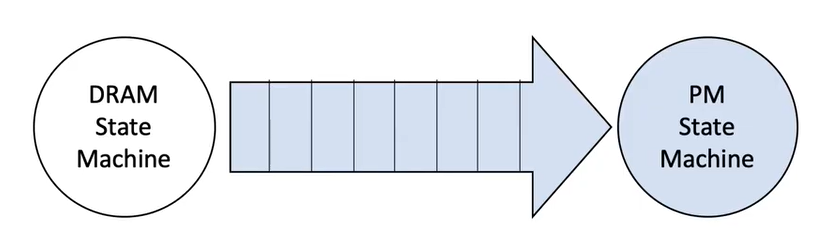
state machine ops should follow:
- no external dependencies. e.g keep file descriptor
- execute deterministically
- no external side effect. e.g. network op
log replay => no concurrency!
PSM (Persistent State Machines) API:
- psm_init(): initialize
- psm_invoke_rw(op): read write op with persistence
- psm_invoke_ro(op): read without persistence
like a middle ware for coding…
pros:
- low coding effort
- low latency
cons:
- cost 2x CPU and space
- shadow execution would be bottleneck when write-heavy workload
implements
dynamic binary instrumentation (undo logging) to ensure PM write's crash consistency.
Optimization:
- undo-log in 32B blocks
- dedup: log each block only once
just a undo logging?
recovery:
- use undo log to reover PM state machines
- shadow execute remaining operations
- copy PM state machine to DRAM
Usage
code modification needed for software upon PSM:

While 3000 lines on Redis built-in PM supports
eval
TAPIR: similar performance with redis…
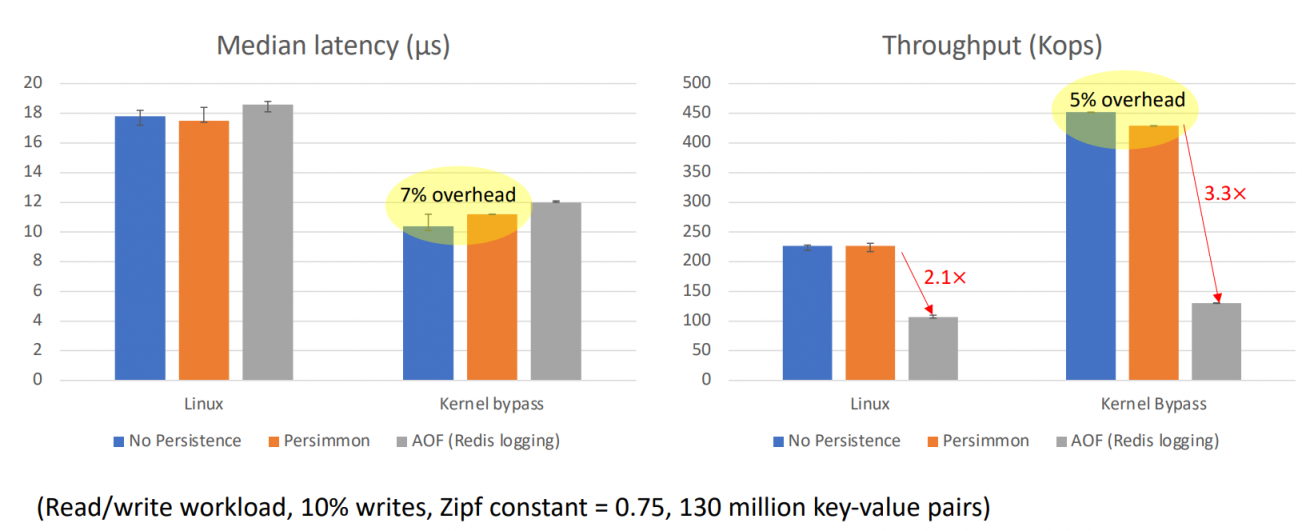
note: it works well for read-heavy workloads, but fastly degenerates after write percentage over 40% because of the logging queue is blocked. While 40~50% write workloads are not rare on real enviroments[2]
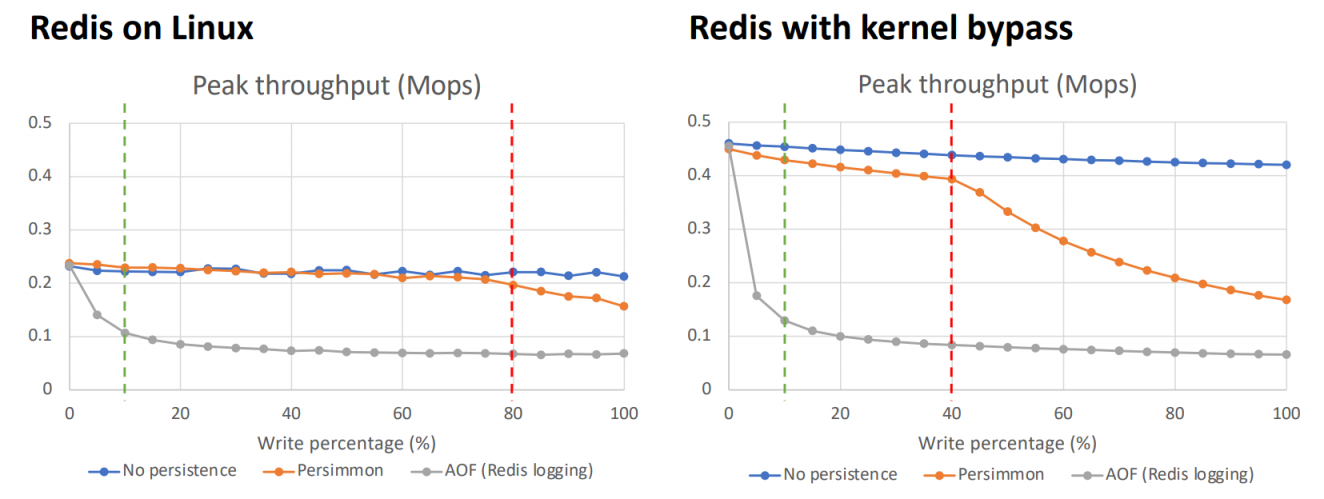 naive logging persistence strategy can handle >10% write workload!
naive logging persistence strategy can handle >10% write workload!
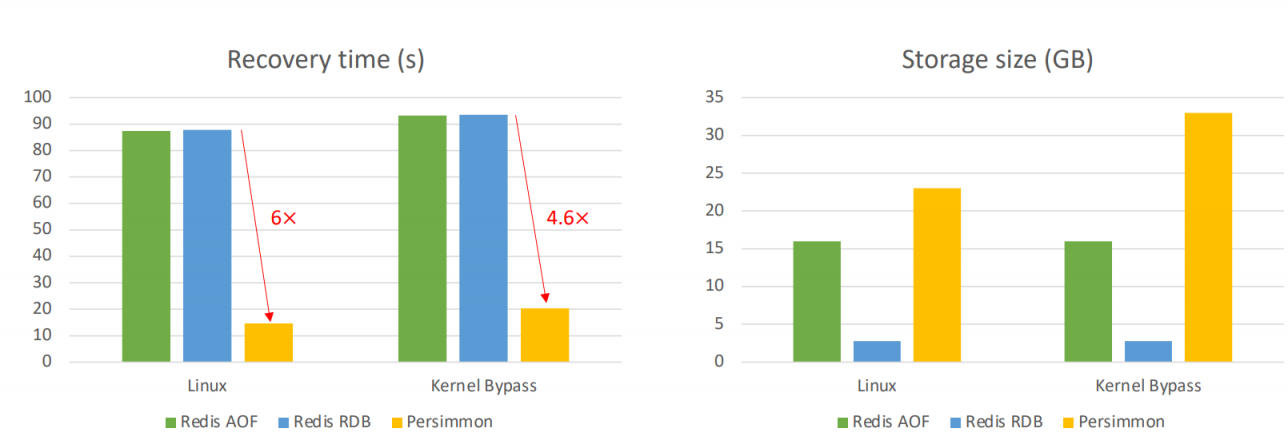 recovery use more space to achieve high speed. but PM is cheaper!
recovery use more space to achieve high speed. but PM is cheaper!
note: ofc, Persimmon is like a local shadow server on PM… And PM is big enough to handle the second storage system
also, persimmon's logging suffers write amplification too.
entries granularity is small and may finally decrease PM write performance, even with some de-dup tricks mentioned in paper.
Besides, DNs on some closely coupling storage system have to handle network io to ensure consistency or something else. This kind of "complex system" can't be modeled by state machines.
Set up multi state machines on a single machine may do help to realize a certain degree of concurrency
refer
[1] Zhang, Wen, Scott Shenker, and Irene Zhang. "Persistent State Machines for Recoverable In-memory Storage Systems with NVRam." 14th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 20). 2020. [2] Yang, Juncheng, Yao Yue, and K. V. Rashmi. “A large scale analysis of hundreds of in-memory cache clusters at Twitter.” Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI’20), Banff, AL, Canada. 2020.