主要讨论osdi 20一篇来自Twitter和CMU的工业界大规模键值存储负载特性的工作[1]。在这之前12年有一篇来自facebook的类似负载特性工作[3]。这篇博客讲讲这两篇工作。
OSDI 20在11月初开完了,菜鸡看不到线上会议。。。感谢交大IPADS的OSDI一手分享[2]。
Workload analysis of a large-scale key-value store
facebook那篇[3]是分析内部memcached集群的280 billion请求的。
read/write ratio
统计中,分出了五种不同特征的负载(数据来自相同性能的memcached实例)。
- USR 用户状态
- APP 应用元数据
- ETC 通用的缓存,也是最大的池
- VAR 服务端浏览器
- SYS 服务位置上的系统数据
不同池子有不同的访问负载特性,如下图
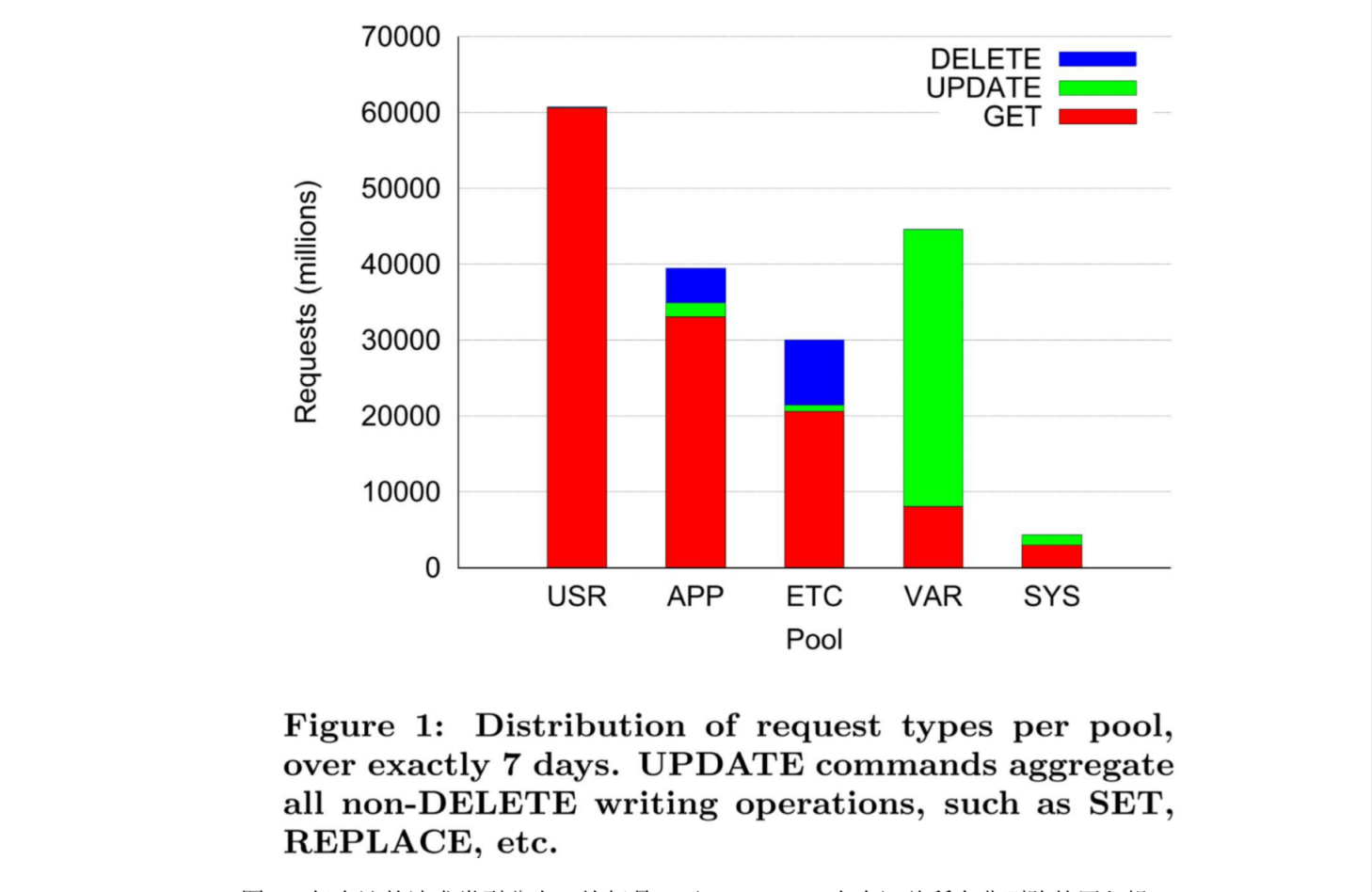
- USR,因为是存状态,很少更新,99.8%都是读(像是个适合持久化的好兑现)。是个按需填充的,所以当发生了未命中才会有写操作。
- APP,DELETE数量比较多。数据来源一般是数据库的缓存,当数据库条目被删除的时候,引发的缓存删除。
- ETC,类似于APP,但是DELETE高一些。这是一个最大、且异构的池子,是本文重点。读写比例为30:1,高于通常的假设。
- VAR,以写为主,存的都是很短期的数据,如浏览器的窗口大小等。
Key value size
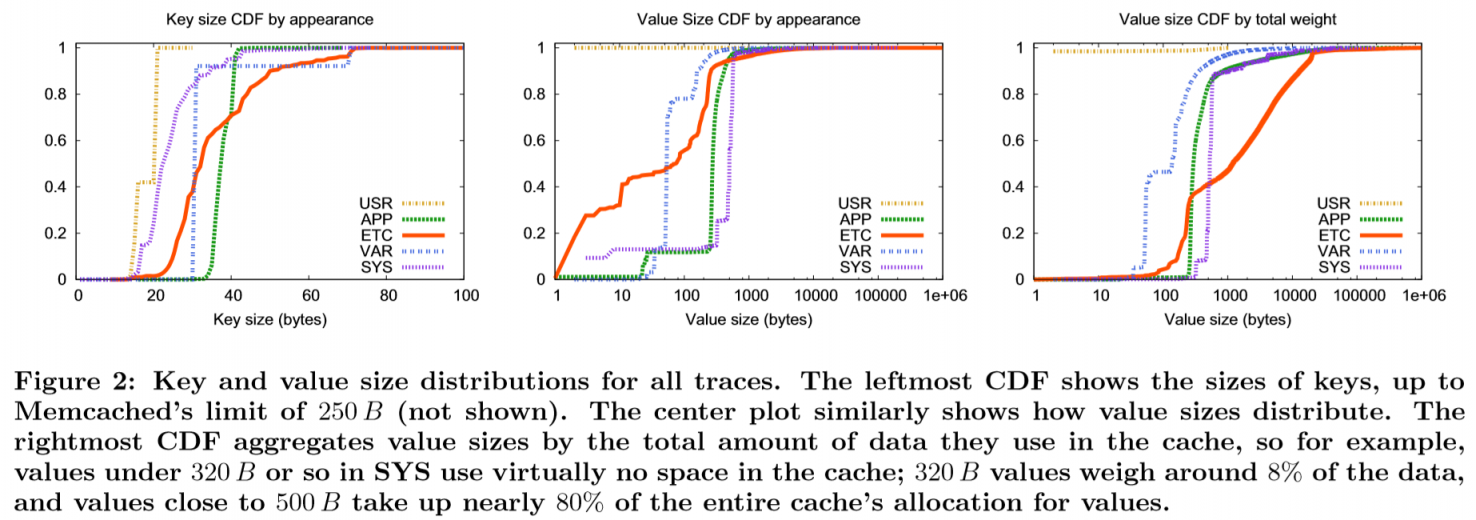
如图三个CDF展示键值数据的大小分布,可以看到值在500B以下的数据占了90%。SYS类别里大部分都是320B以上的值(92%)。【by total weight指的是通过访问数量加权的】
在除了ETC以外的池上,特征比较明显,如APP的都是小key,USR的key长只有两种。
在ETC上,有1MB的大value,也有占总请求数目40%的11B小请求。
大量的小请求会引发1.网络开销占主导,2.内存碎片。
因此batching,slab的优化效果会非常明显。
话说memcached只支持key最大到250B,大key的数据会不会影响数据采样呢?
temporal pattern (时间模式
高峰出现在欧洲和北美的白天。
cache behavior

 比较明显的特征就是USR的命中率随着时间而上升,因为在启动后,通过PUT逐渐提升USR池的命中率。
比较明显的特征就是USR的命中率随着时间而上升,因为在启动后,通过PUT逐渐提升USR池的命中率。
locality
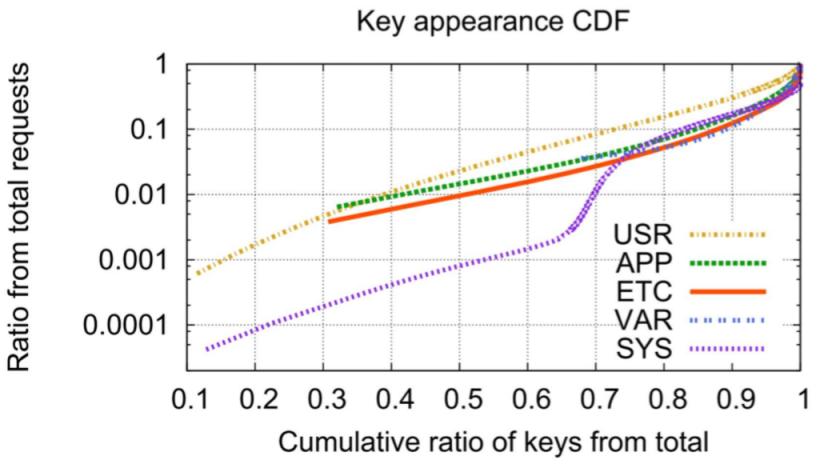
ETC池里有50%的key只出现一次。而有的key能出现百万次,就很适合优先缓存下来。除了SYS以外,其他曲线都比较类似。作者认为SYS第一次转折是因为启动导致的,后面的曲线才是正常的SYS场景。
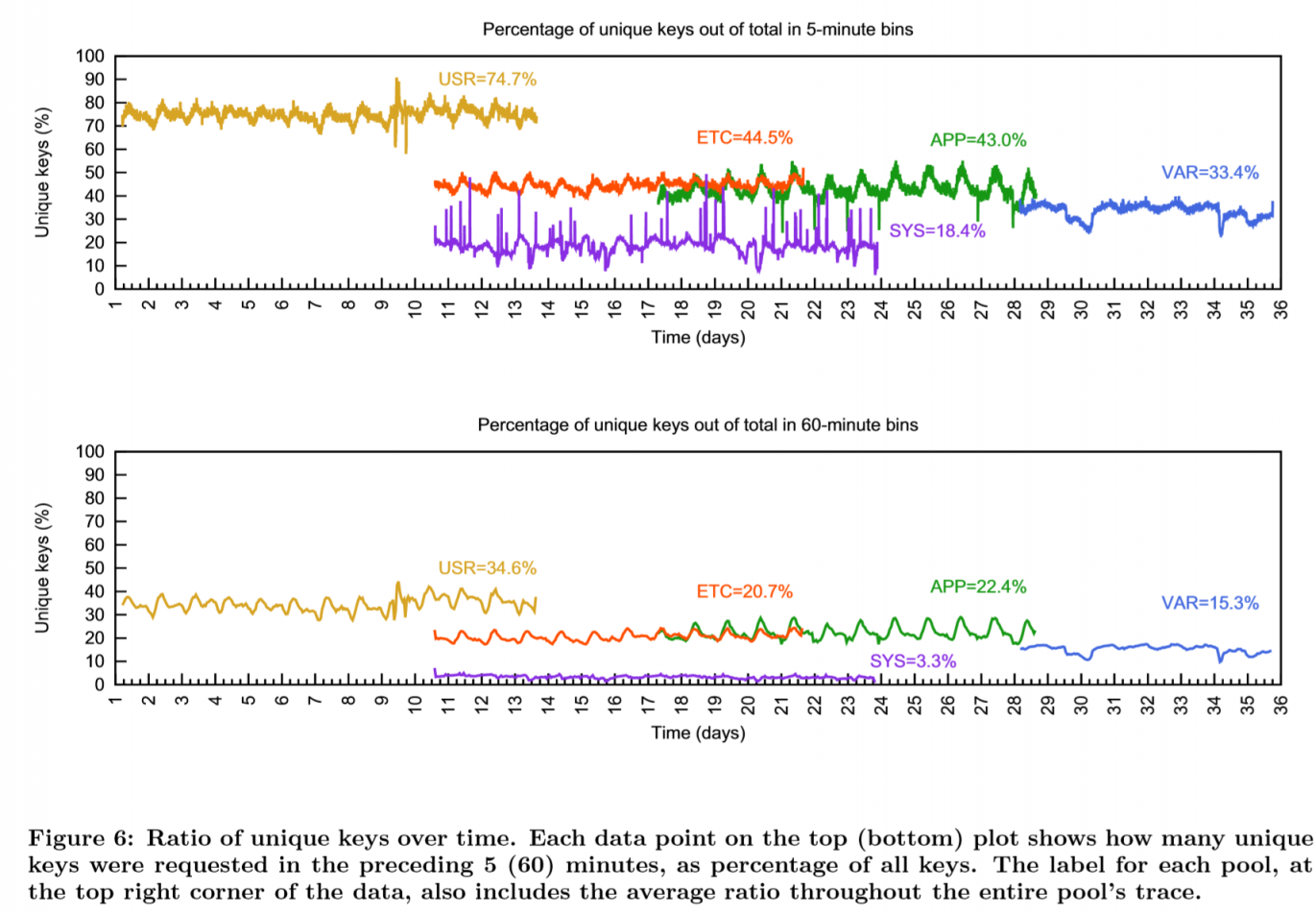 SYS的不重复key只有3.3%,而USR则高达34.6%
SYS的不重复key只有3.3%,而USR则高达34.6%
对比上下两图,可以发现大多数的key一小时内,被访问概率是快速下降的,通常这能够导致更高的整体命中率。在键的重用周期统计的实验部分,这个下降的时间可以长到300+h。ETC池的重复key,从一小时的88.5%下降到4%。

通过对ETC的命中率的研究,发现ETC的命中率即使在很大的RAM上也只能达到80%。其中大部分miss来自访问超过10天前的数据。
因为1%的访问到了50%的数据,demand-filled cache基本无意义。
statical modeling

inter-arrival gap(两次到达的间隔)和key大小、value大小,三个属性互相都不相关。
然后分别对这三个属性做模型拟合建模,具体见原文。
ETC基本符合Zipf's law
通过测量miss GET和恢复该值的后续SET过程的开销来估算miss的开销。这个开销和值大小成正比。因此字节命中率这个指标并不重要,而应该关注命中率(较小的值更重要)。
文章后面说,“替换策略、分配策略都大有文章可做。可以研究动态slab或slab-free的分配方法”,slab除了元数据管理开销比较大,有啥缺点呢?
A large scale analysis of hundreds of in-memory cache clusters at Twitter
采集了twitter 153个集群超过80TB的数据,通过twitter魔改的memcached和redis。
[1]给了三个用途分类
- storage,当database用的
- 读为主,cache命中率很高,α of zipf很大
- compute,计算的中间结果,具体特征取决不同类型的计算
- ML类型的都是读为主,很符合zipf
- mapreduce等需要存中间值的,就会写为主,比较偏离zipf,TTL更短
- cache,短时的cache
read/write ratio
在>35%的集群上都是写密集的(>30%)【常见于compute场景中】。
这个指标比facebook ETC负载要高很多
object size
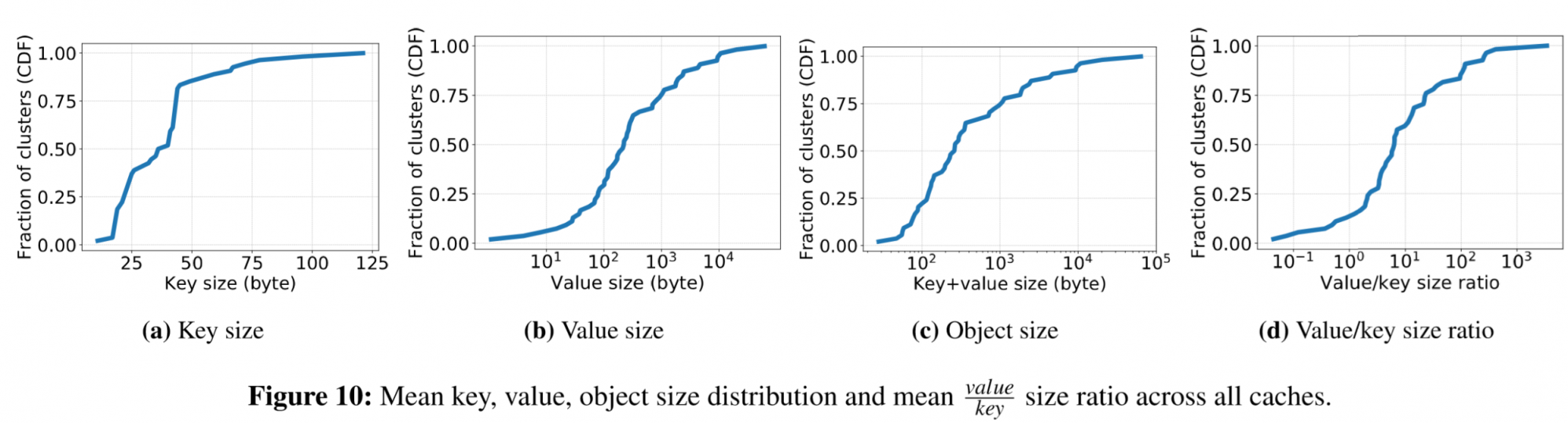
在键值大小上,24%的集群的平均值大小小于100字节,中位数在230字节。
Figure 10a shows that around 85% of Twemcache clusters have a mean key size smaller than 50 bytes, with a median smaller than 38 bytes. Figure 10b shows that the mean value size falls in the range from 10 bytes to 10 KB, and 25% of workloads show value size smaller than 100 bytes, and median is around 230 bytes. Figure 10c shows that CDF Figure 10a shows that around 85% of Twemcache clusters have a mean key size smaller than 50 bytes, with a median smaller than 38 bytes. Figure 10b shows that the mean value size falls in the range from 10 bytes to 10 KB, and 25% of workloads show value size smaller than 100 bytes, and median is around 230 bytes. Figure 10c shows that CDF distribution of the mean object size (key+value), which is very close to the value size distribution except at small sizes. Value size distribution starts at size 1, while object size distribution starts from size 16. This indicates that for some of the caches, value size is dramatically smaller than the key size. Figure 10d shows the ratio of mean value and key sizes. We observe that 15% of workloads have the mean value size smaller than or equal to the mean key size, and 50% of workloads have value size smaller than 5× key size. 另外因为memcached就用了56字节做元数据,这很影响缓存的命中率。
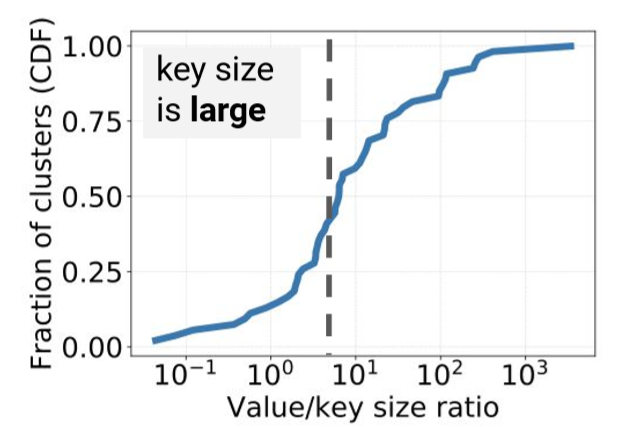
文章还探讨了键和值的比例关系。15%的集群上键的大小大于值,50%的集群上5*键的大小大于值。
原因是因为很多应用在使用键时,命名空间(前缀)占得部分很长。如ns1:ns2:obj。
所以以后可以做key压缩。所以整个unique id还是有必要的
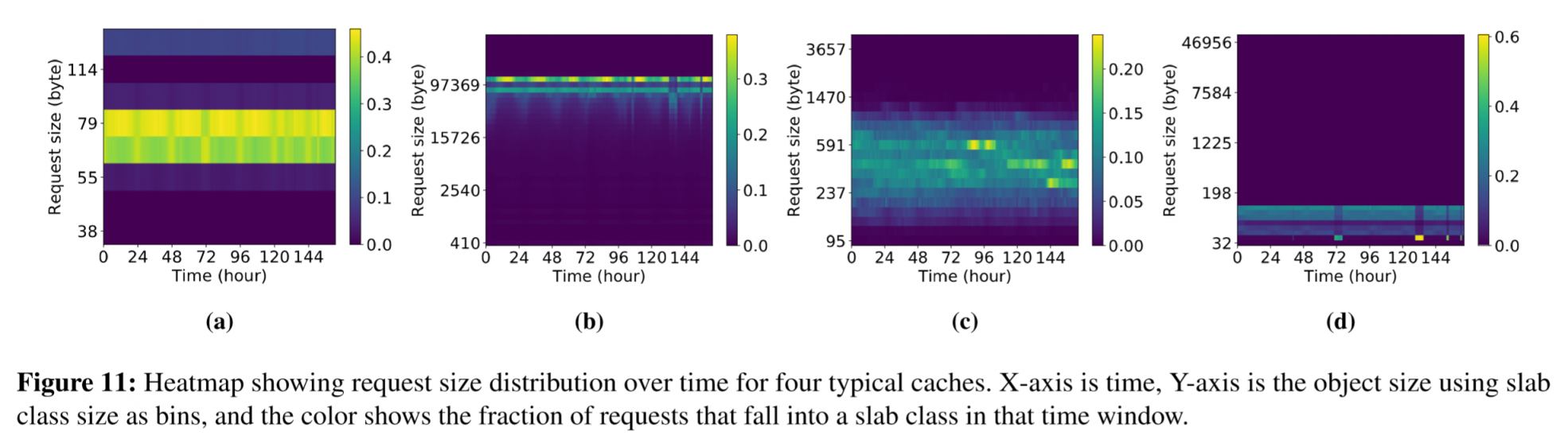
同时访问的大小并不是静态的。上面的热度图展示了object size随着时间的变化而变化的情况。导致这个现象的原因有很多,比如同key的value随着时间增长,或访问受时差访问之类的影响。
这样的问题会对内存分配系统造成挑战,很难预测未来大小解决碎片化问题。
slab分配也会遇到slab钙化的问题。
TTL
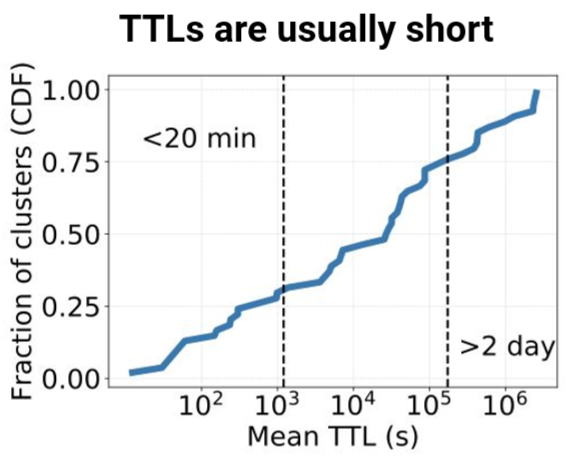
大部分数据的TTL都很短,大部分数据小于48h。所以设计一个好的清理过期数据的方法很重要,甚至很多系统上,这比缓存替换更重要。
这点和上一篇差不多,cold-hot分级存储启动
popularity (locality)
基本符合zipf。一个小 区别在于最热的数据不会zipf那么热,最冷的数据比zipf更冷。
这里原文说facebook那篇说负载不符合zipf。明显没看仔细,那篇文章说的是一些强特征的池不符合而已,ETC还是很符合的。
cache evict
LRU除了在cache非常小的情况下,效果和FIFO很接近。系统就更注重简单、不会引起碎片问题的替换算法。
实验选择的替换算法很少,就是不同粒度的LRU和FIFO
others
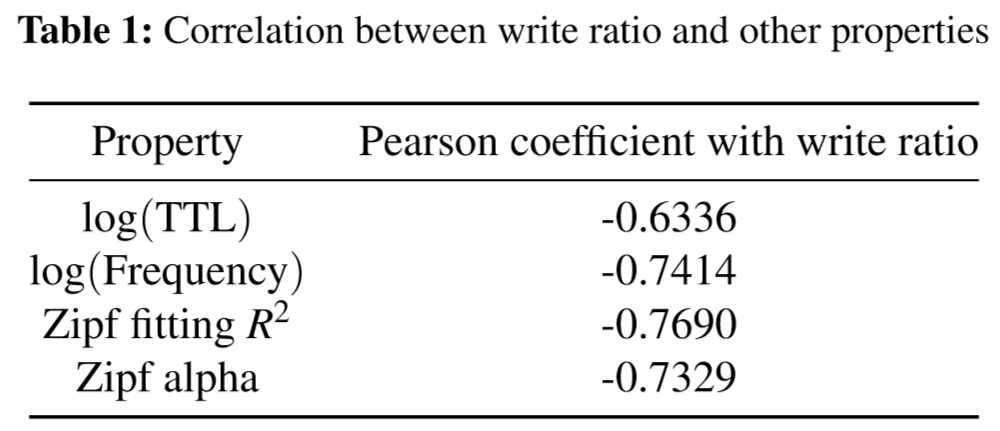
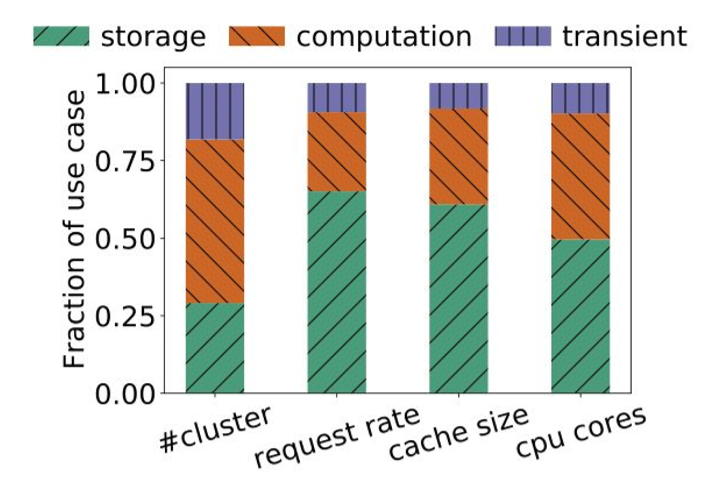
读写比例和TTL、Zipf参数等指标相关性很强。如更高的写比例,一般就会有更短的TTL。
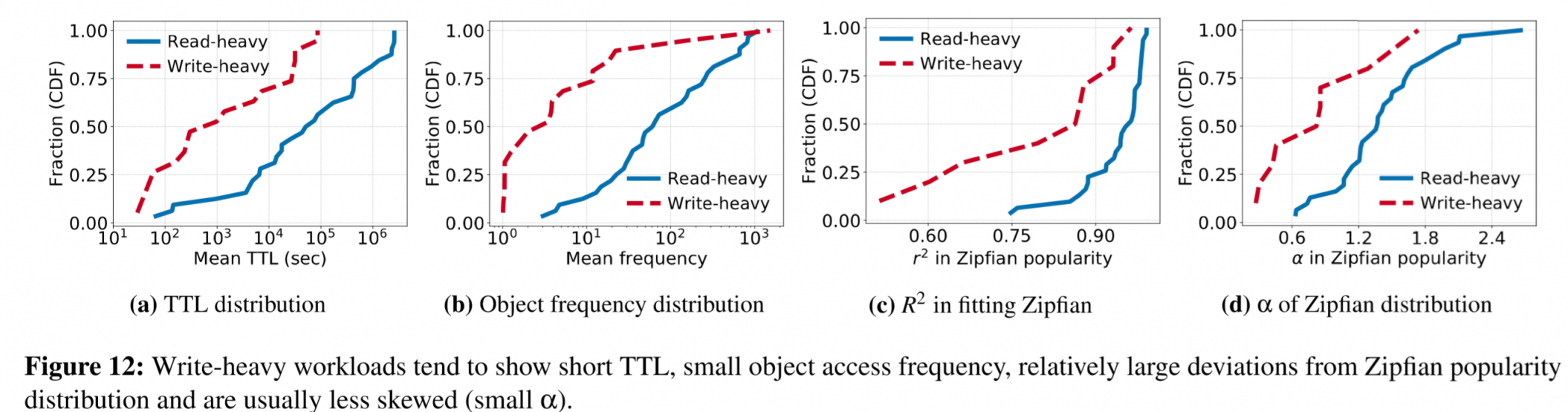
影响效果如下图所示
ref
- Yang, Juncheng, Yao Yue, and K. V. Rashmi. "A large scale analysis of hundreds of in-memory cache clusters at Twitter." Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI’20), Banff, AL, Canada. 2020.
- OSDI2020——SJTU-IPADS的“云见闻”(一)
- Atikoglu, Berk, et al. "Workload analysis of a large-scale key-value store." Proceedings of the 12th ACM SIGMETRICS/PERFORMANCE joint international conference on Measurement and Modeling of Computer Systems. 2012.