TH-DPMS: Design and Implementation of an RDMA-enabled Distributed Persistent Memory Storage System, 舒继武老师组的新工作,发在ToS 2020。 关于RDMA+PM的分布式存储系统,在一些sota方法的基础上搭建了一个分布式PM系统,以及之上的FS和KVS
Architecture
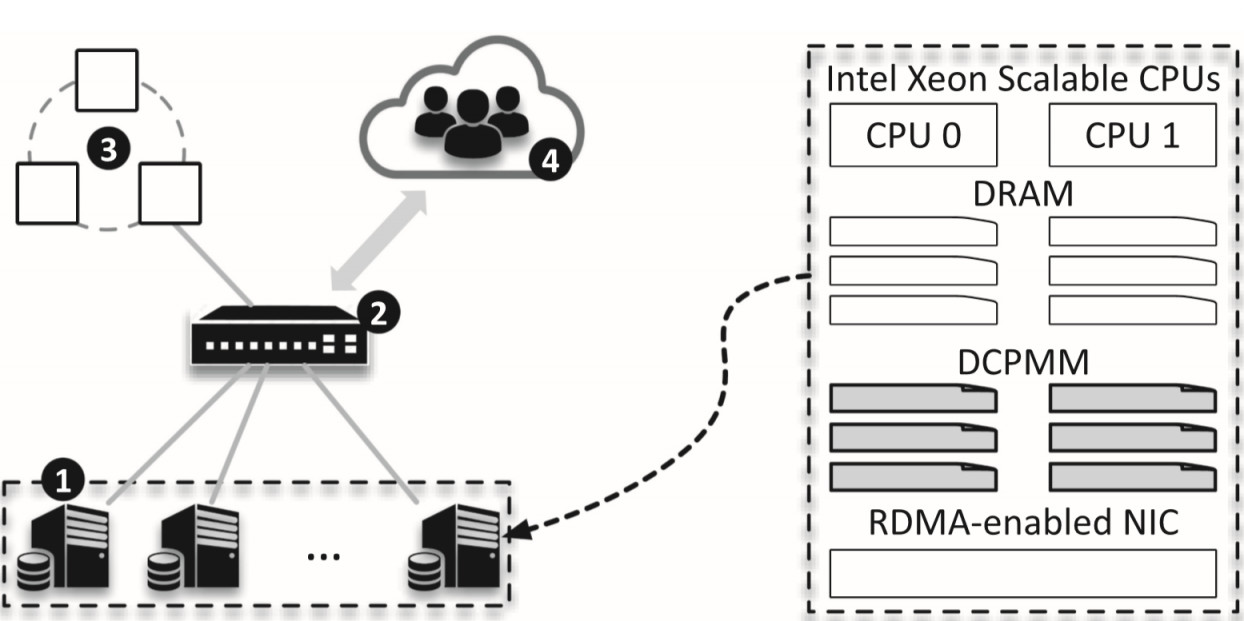
有以下几种角色:
- PM servers,即DN
- RDMA switch
- global monitor,管理全局信息
- client,跑应用
为了双socket平台设置双RNIC去除NUMA的影响
数据放置【下图中global addr management】:
- 小数据:从低位开始分配,oplog同步堆分配方式的数据
- 大数据:从高位往下分配,client主导的主从副本机制
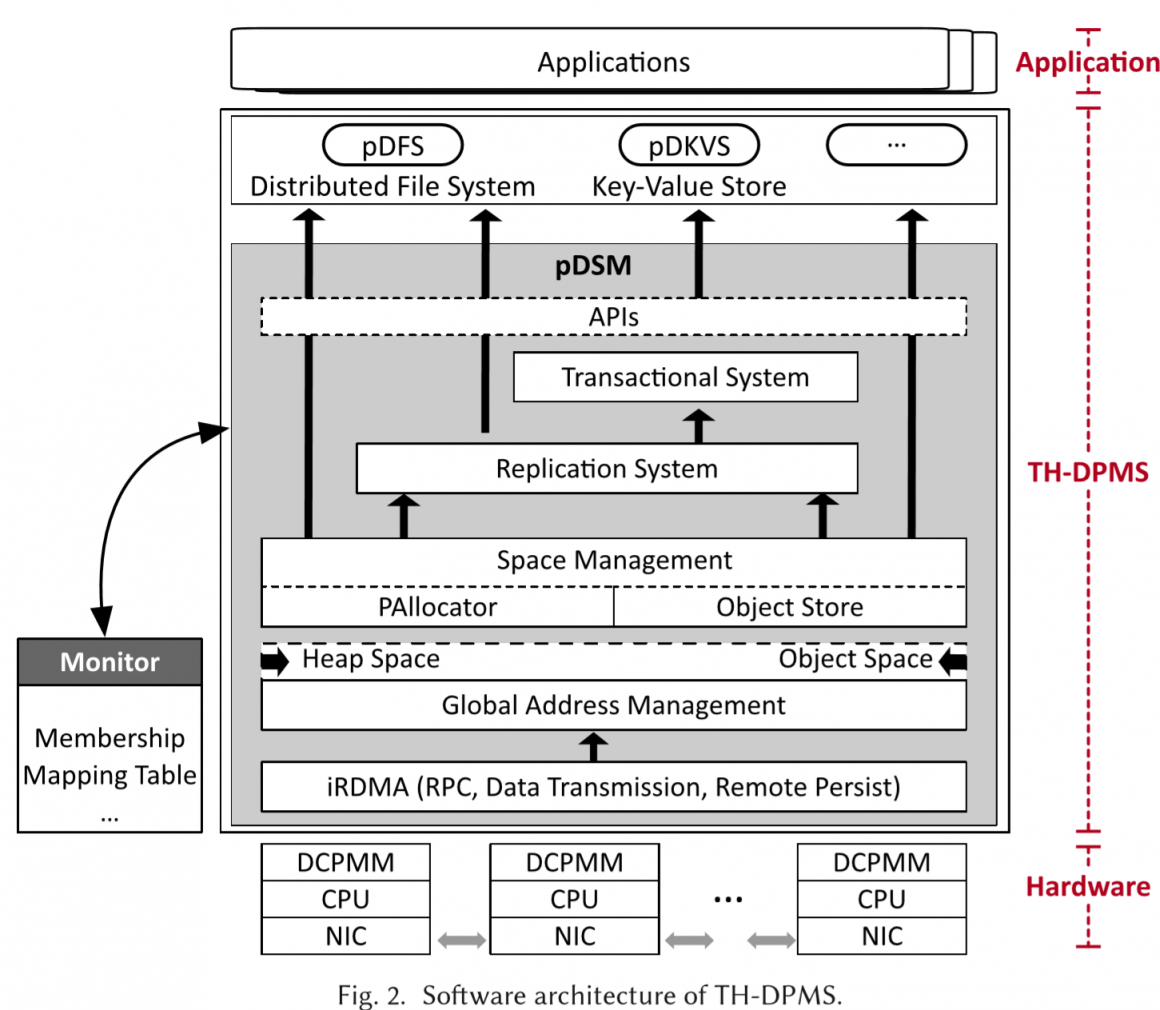 如图所示为系统的层次结构
如图所示为系统的层次结构
pDSM
iRDMA
为了减少竞争,单个核心对单个核心通信。不对称的配置有额外trick。 效果:能扩展到2000台36核心的机器。CX-5 IB硬件能支持在60K个连接上,10%的性能损失。
RPC设计参考Octopus[1]。全部通过RC建立。 imm的大小32位不够寻址用,大部分寻址前会有次双向通信,所以可以提早通知后端寻址信息。实在不行就用普通RPC。 zero copy很难,因为应用会在没有向NIC发起申请的情况下自己创建自己的buffer。但如果一个个ibv_reg_mr很慢。设计了一个中转的buffer池。
global address management
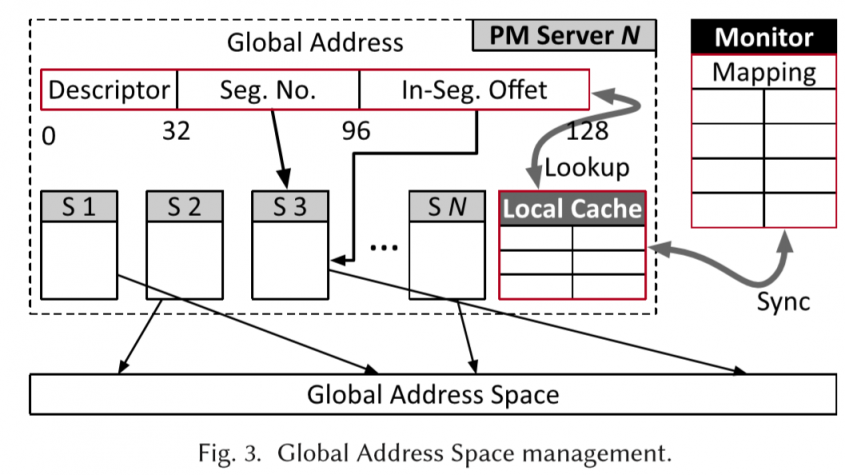
地址分配上,有个类似两层页表的机制,分成2GB的大页(也是replica, recovery的基础单元)。通过seg no和seg offset映射到三个replica的实际地址(<Node id, offset>)
每个地址128位长,形式为 <Descriptor, Seg NO, In-seg offset>
Descriptor主要是描述segment的元数据,比如权限位、副本数量等。
整体的结构还是一个页表形式。这个页表持久化的存在monitor上。pm server在访问的时候,会cache自己访问的部分。
集中把PM空间全部注册了会有权限问题(单次分配就无视了RDMA的权限管理机制)。因此以2GB的segments为单位进行注册,也以这个单位大小作为权限管理的基础单位,拿到注册号的segment对应key的client就可以对这个区域进行操作(永久授权)。
2GB的segments设计也简化了副本同步的开销。
centralized monitor
monitor是用来维护全局配置的。
为了避免monitor成为瓶颈,用了三个机器通过Raft做共识。
每次client发起一次分配请求时:
- PM server先检查权限,划个可用的segment,然后把key, node id, offset, r_key发送给monitor
- monitor给这个segment找一个在映射表里合适的全局地址
- monitor向其他PM server请求个backup segment(随机选取,这里其实可以做负载均衡)
- monitor收到消息后,才插入数据到映射表里。然后返回这组映射关系给PM server。
- pm server会cache下映射关系。然后操作这个新的segment。
在集群管理上,由于可能加入新机器,或有机器因为故障退出,配置会有改变。因为client等机器会cache位置,为了维护数据的一致性。设置了一个epochID(类似Clover[2]的GC version)。
每当有配置变化,monitor会更新映射表,自加epochID,广播给PM servers,PM server再更新本地的cache。
client端的cache持有epochID,client请求时会带上它持有的epochID,PM server就能判断是否在请求一个过期的位置。
类似Clover的,版本号在同步上会有窗口期,即配置已经改变,但client还没有得到更新,的这段时间内的请求,会由timeout打断。
因为这里的monitor只管理2GB segments粒度的请求,还有配置变化后的维护,不在性能关键路径上,所以不会成为瓶颈。
PAllocator
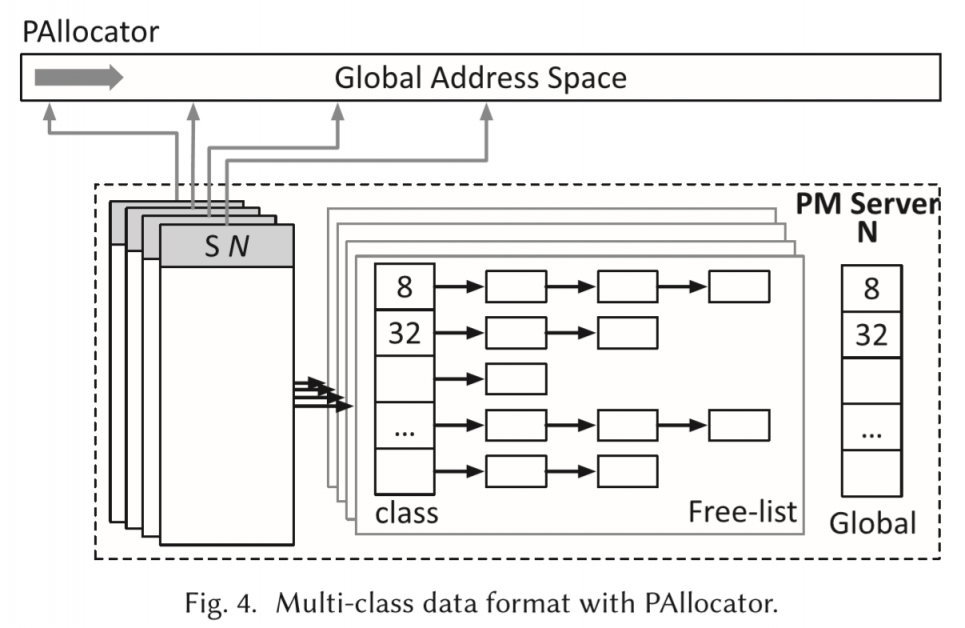
PAllocator就是在PM上细粒度的分配器。把2GB的segment切成4MB的chunk。chunk内部再切分成多个等长block。chunk头部有元数据,记录block的长度、记录blocks使用情况的bitmap等。
在内存上维护了多个free list(对应多个segments)来保存未使用的多个不同级别的blocks,防止scan bitmap太慢。(那为啥要bitmap呢。。)再维护一个global allocation table来索引free-lists。
类似NOVA[3],为了提升scalability,不同的核心管理不同的chunks,有自己的global allocation table。有请求来时,就从自己持有的,合适级别的chunk里分配block。
Object Store
前面提到对象存储从高位地址往下用。用一致性哈希objectID到node。
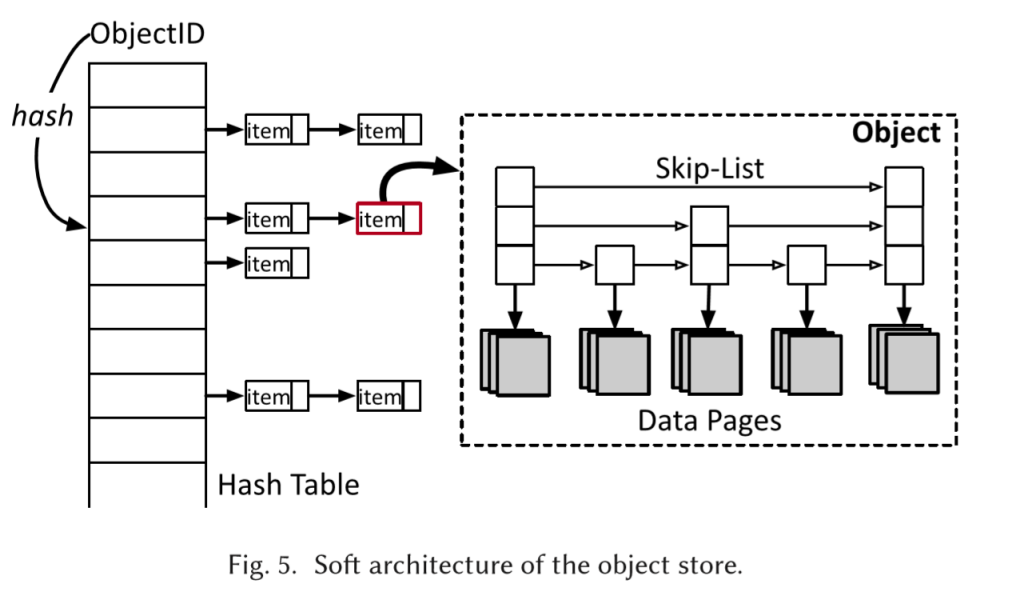 在数据的索引上,通过objID哈希到简单拉链的哈希表上。每个item内用跳表索引具体的数据页。CoW更新数据页。这里的数据页可能是跨segments的,但一定要是同机器的。
在数据的索引上,通过objID哈希到简单拉链的哈希表上。每个item内用跳表索引具体的数据页。CoW更新数据页。这里的数据页可能是跨segments的,但一定要是同机器的。
Distributed Transaction
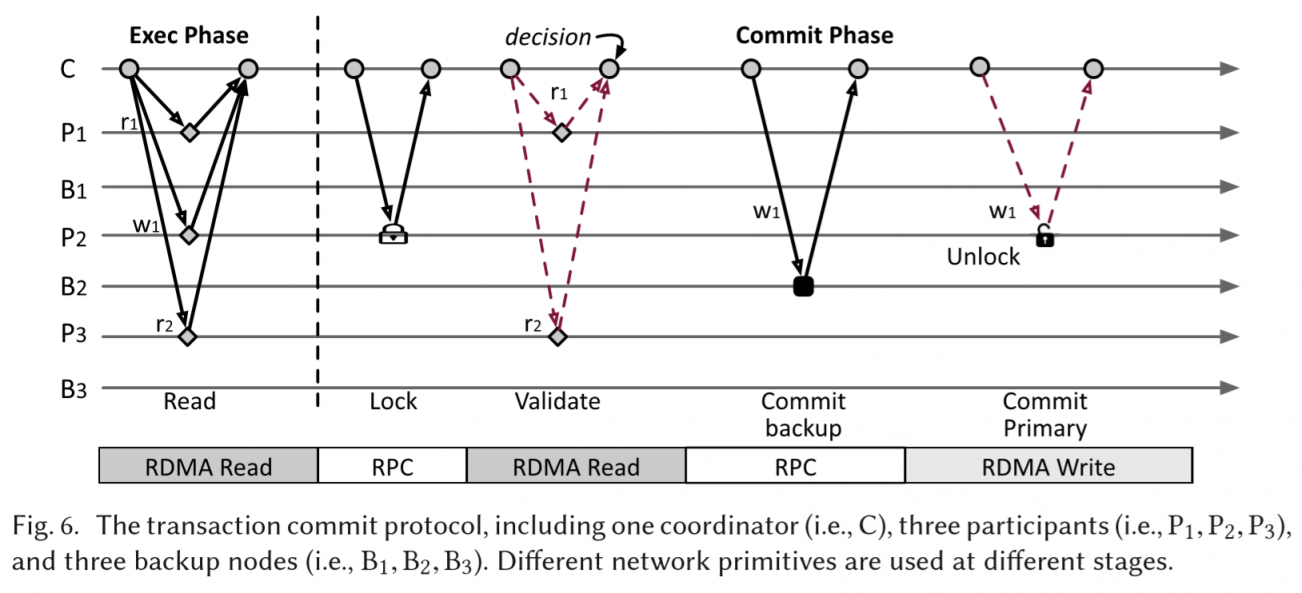
用FaRM[4]的那一套分布式事务。就是2PC。
如图所示举例子
- RDMA read,读取本次事务相关的item。
- Lock,coordinator请求被写入位置的锁,同时也把待写入的数据发给participant
- Validation,coordinator通过RDMA read检查版本号是否正确。
- Commit bakcup
- Commit primary
因为事务操作都是在PM上做,所以可以recovery。
replication
segment是replication的最小单位。在小粒度上(比如在地地址区域更新了堆),强制应用通过事务的方式来更新。
object这种大粒度的,则单独通过RDMA write来同步。
pDFS
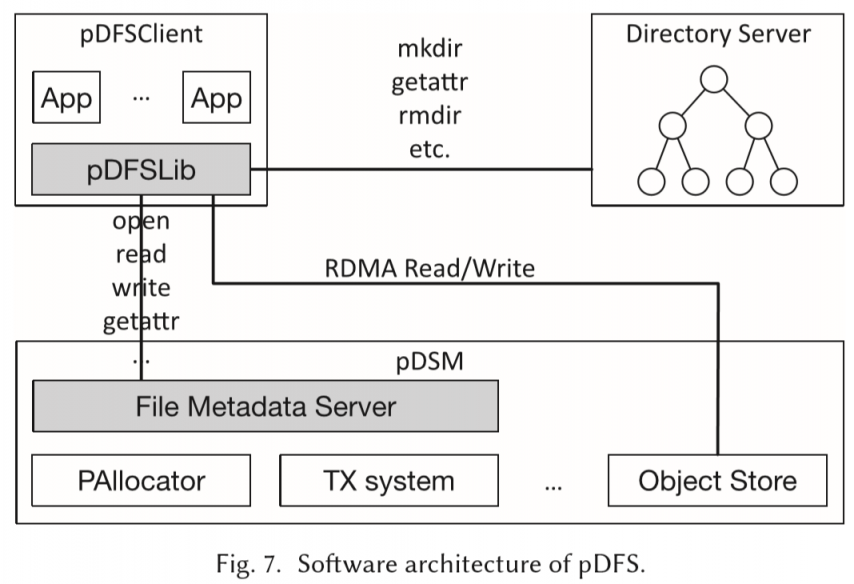
pDFS在pDSM上做了一层文件系统。
如图有四个角色:object store, file metadata server, directory metadata server, pDFSLib。
参考LocoFS[7]和Octopus:
- 用了一个和director绑定的GUID来保证对path hash不会在rename后结果变化。
- 用了client-active data I/O,回复包带地址不带数据,client通过One side verb read来读取。把后端CPU的负载转移到网络上。
pDKVS
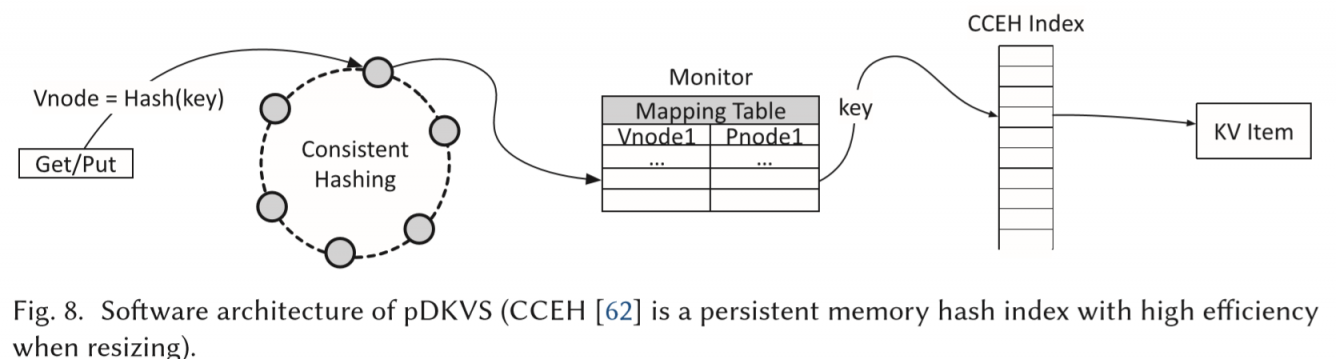
pDKVS在pDSM上做了键值存储系统。
- key通过和monitor通信,使用一致性哈希计算分散到不同的PM server
- PM server上通过CCEH[5]索引到指向数据的指针。(KV分离)
CCEH不需要额外的log来支持崩溃一致性,但需要用事务来保证和副本的一致性。
Experiments
系统原型实现上,没有基于PMDK,觉得PMDK的额外机制太多太复杂了。
KVS
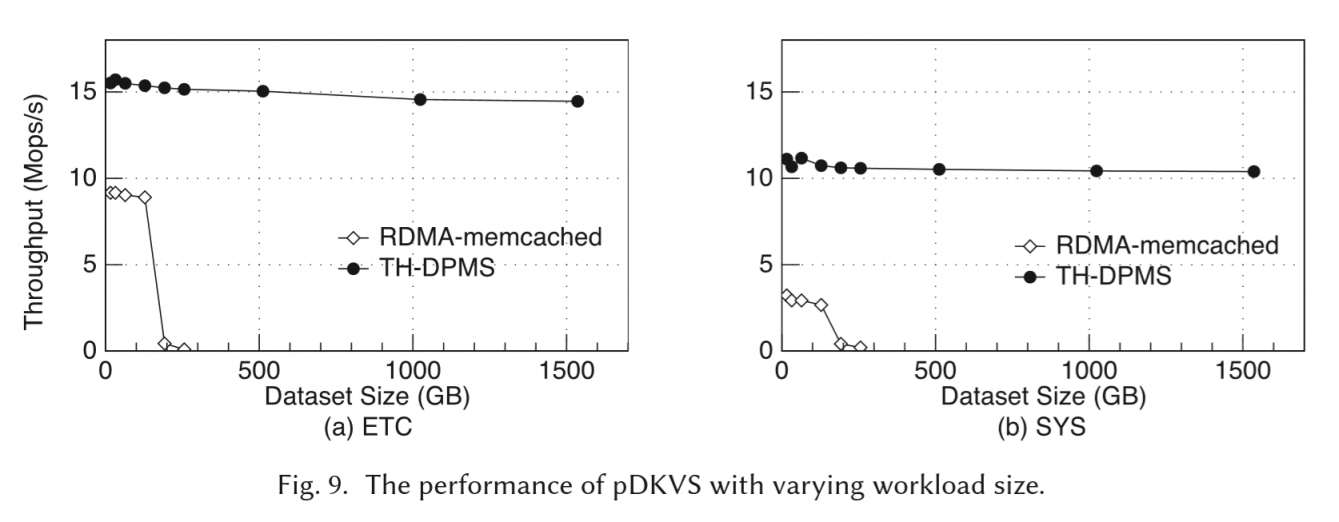
在facebook的KVworkload上测试,和RDMA-Memcached对比(没有早期工作,Clover算是同期工作吧)。在ETC和SYS上1.7X~3.5X差距。
RDMA-Memcached的GET/PUT都要多个round trip。因为DRAM就128G,workload太大后swap换页,性能掉得很明显。
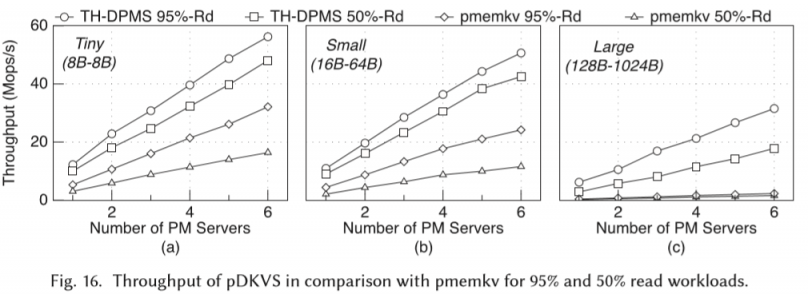
上图则是改变item大小、PM server数量、读写比例,和Pmemkv[8](原来是单机的,用本文的RPC来扩展)做对比。因为Pmemkv为了保证崩溃一致性,做了比较复杂的logging策略。性能表现在1.7~2.9x
RPC测试
拿iRDMA和eRPC[6]对比(eRPC是RPC的sota。NSDI '19的best paper,不要和开源的eRPC弄混。)
平均延迟低18%,99th的尾延迟低47%,吞吐量高1.2x。
作者认为低延迟来自于write_with_imm的设计。【那为啥不和你们做的Octopus比。。。】
带宽测试
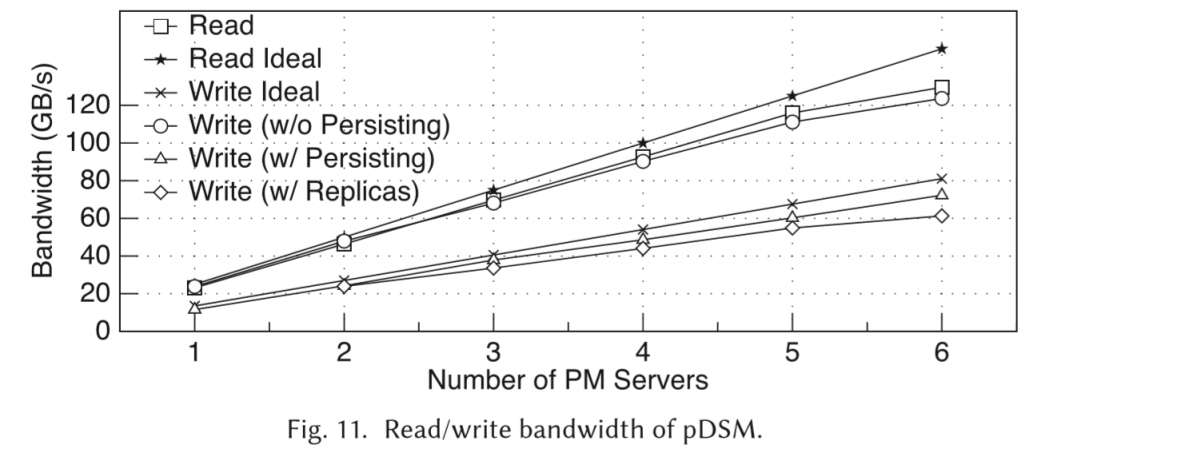
基本随着PM server数量增加而线性增长。
YCSB
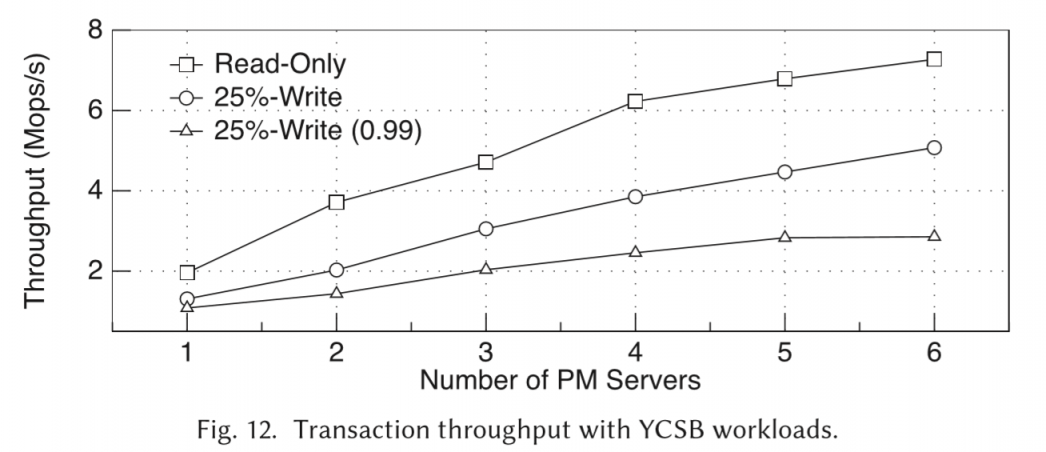
failure
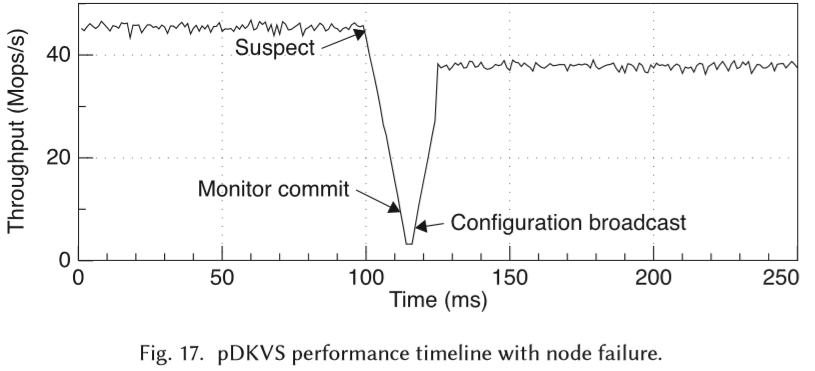 因为monitor发起的心跳包很频繁,所以很容易发现某个PM server挂掉的现象。重新构建的过程小于30ms。config这部分元数据只有几MB,很小,更新过程也很快。
因为monitor发起的心跳包很频繁,所以很容易发现某个PM server挂掉的现象。重新构建的过程小于30ms。config这部分元数据只有几MB,很小,更新过程也很快。
Filebench
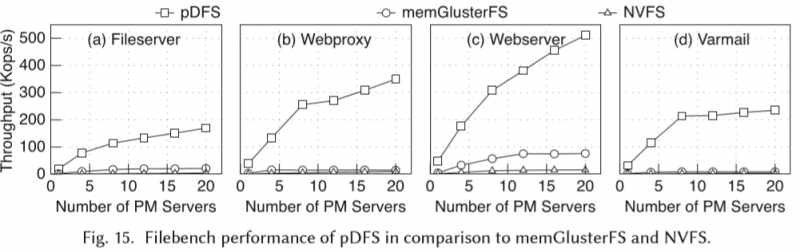
refer
- Lu, Youyou, et al. “Octopus: an rdma-enabled distributed persistent memory file system.” 2017 USENIX Annual Technical Conference (USENIX ATC 17). 2017.
- Tsai, Shin-Yeh, Yizhou Shan, and Yiying Zhang. “Disaggregating Persistent Memory and Controlling Them Remotely: An Exploration of Passive Disaggregated Key-Value Stores.” 2020 USENIX Annual Technical Conference (USENIX ATC 20). 2020.
- Xu, Jian, and Steven Swanson. “NOVA: A log-structured file system for hybrid volatile/non-volatile main memories.” 14th USENIX Conference on File and Storage Technologies. 2016.
- Dragojević, Aleksandar, et al. “FaRM: Fast remote memory.” 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14). 2014.
- Nam, Moohyeon, et al. "Write-optimized dynamic hashing for persistent memory." 17th {USENIX} Conference on File and Storage Technologies ({FAST} 19). 2019.
- Kalia, Anuj, Michael Kaminsky, and David Andersen. "Datacenter RPCs can be general and fast." 16th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 19). 2019.
- Li, Siyang, et al. "Locofs: A loosely-coupled metadata service for distributed file systems." Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 2017.
- https://github.com/pmem/pmemkv