Abs
Clover,一个基于RDMA+NVM后端的分布式键值存储系统。通过MDS+DS(MS+DN)的分离元数据与数据的设计,进行运算和存储解耦,提升扩展性。
Backgruond
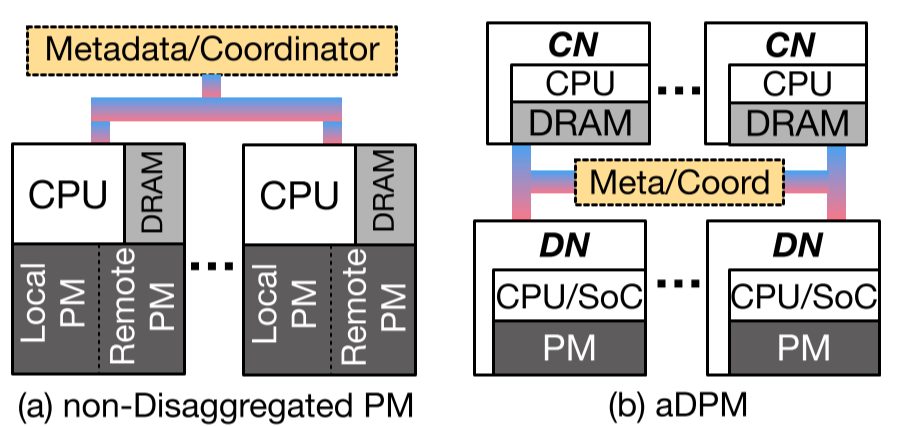 普通的分布式NVM系统是每个node都是对称的,拥有CPU、DRAM、NVM等各种部件,不同节点通过网络通信,在扩展性上比较差。Disaggregated PM(DPM)把存储抽离出来,client node(CN)和data node(DN) attached CPU+NVM通过网络通信。
普通的分布式NVM系统是每个node都是对称的,拥有CPU、DRAM、NVM等各种部件,不同节点通过网络通信,在扩展性上比较差。Disaggregated PM(DPM)把存储抽离出来,client node(CN)和data node(DN) attached CPU+NVM通过网络通信。
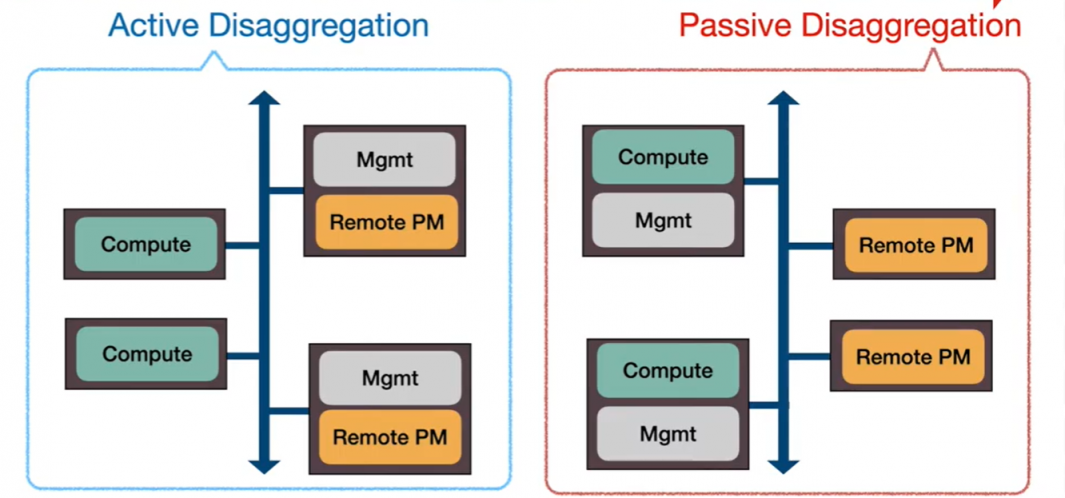
而passive disaggregated PM区别于active disaggregated PM,Data Node(DN)不参与运算,只负责响应RDMA对NVM的读写请求。[e.g. Octopus等]
作者以两个pDPM简单原型,pDPM-Direct,pDPM-Central作为例子来引出Clover。
只看Clover的话,可以直接移步Clover部分。
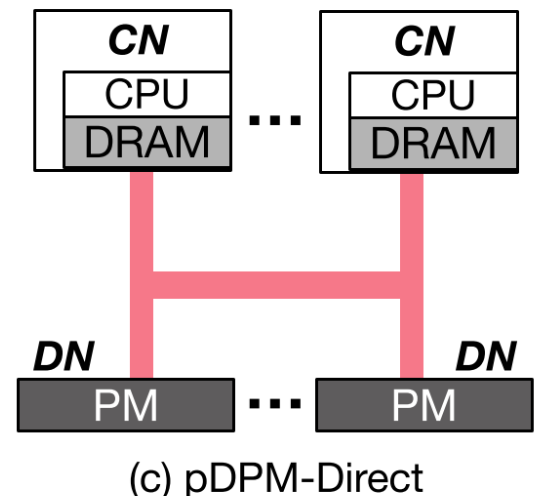
pDPM-Direct
Direct指的就是client直接通过RDMA单向verb来读取DN上的NVM。数据和控制流都从CN发起。
challenge:
- CN怎么分布式地管理DN?
- CN怎么分布式地调度自己的对DN的并发请求?
solution:
在DN上预分配出KV entry的空间,每个entry有committed和un-committed两部分,每个部分内自带一个checksum。
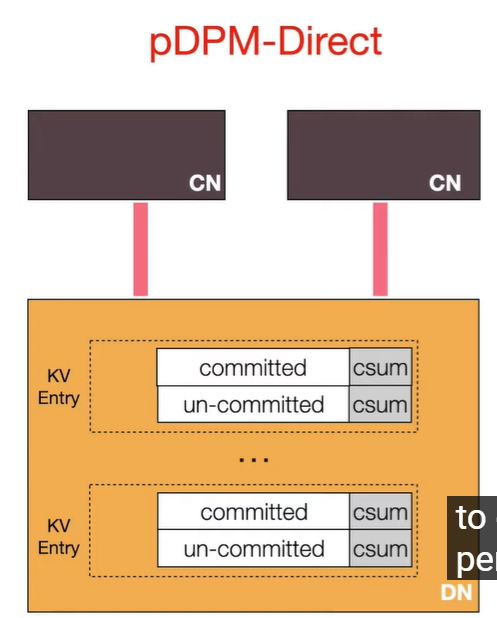
write:
- 通过RDMA CAP上锁
- 写入数据和校验码到uncommitted,作为一个redo copy
- 写入数据和校验码到committed
- 释放锁
read:
- 先读committed的数据和检验码
- 计算checksum,校验成功就读取成功,如果失败,就retry(正有人write)
缺点:
- 写入两次,慢
- 数据上的话,checksum计算慢
pDPM-Central
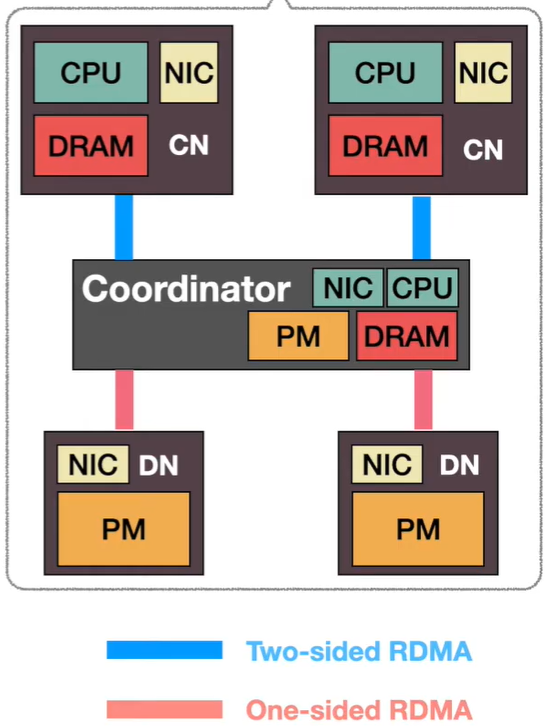
Central就是有一个中心的coordinator来作为中间层。coordinator管理元数据,通过本地的锁来调度CN的读写。用table维护key对应的数据地址,每个entry对应一个锁。
write:
- CN发一个双向RPC给coordinator。
- coordinator分配一个新空间给数据
- coordinator写入这个数据
- 拿锁,更新table,放锁
read:client通过coordinator锁entry读(coordinator通过双向RPC发数据)
缺点:
- 读写都要要2 RTTs,慢。
- coordinator限制了扩展性。
Clover
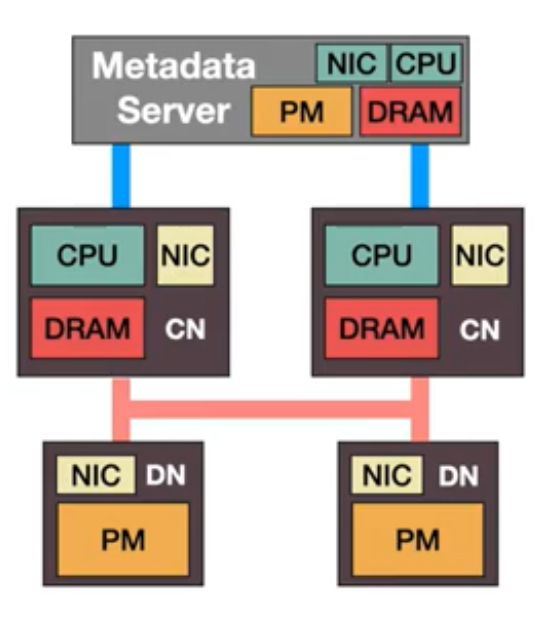
通过Direct和Central版本,引出了Clover的设计:
- 分离访问metadata和data的路径,CN通过单向verb访问DN的mem,双向verb来访问MDS
Data Plane
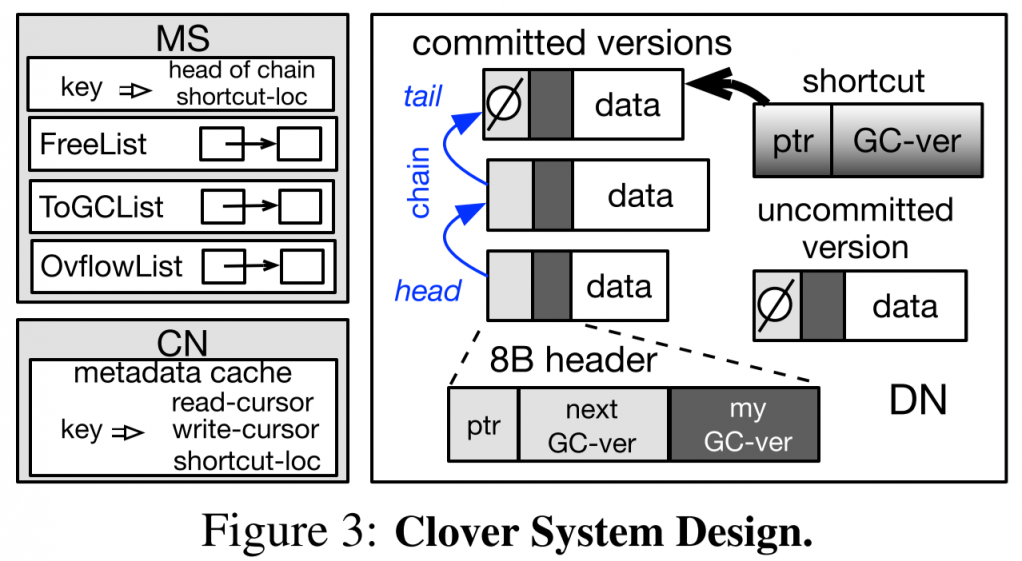
写入时使用一个无锁的异地更新方法(Lock-free out-of-plane write)。
- 在DN上,维护一个链表来存储一个entry的多个版本,每次更新就在链表尾部添加。
- 读取或更新时,都通过缓存的位置开始遍历链表至尾部
- 在CN上缓存热数据的尽可能最新entry的位置。
- 更新时,先通过RDMA write写入数据到DN上。然后找到尾部结点,通过CAS更新链表尾结点的指针,最后更新CN上的位置缓存。
Shortcut read
并发多了之后,链表会很长,而且CN上的cache可能很落时。所以在DN上再额外维护一个shortcut针,指向尽可能最新的数据。
有两个起点,一开始就可以并发读,看哪个新或哪个先返回。
而shortcut的维护需要靠写入结束后,CN再次通过RDMA write更新shortcut。
基于以上的设计,除了两个writer同时更新一个entry,不然都不会遇到竞争的情况。
所以一旦出现这样的竞争,性能会明显下降。
Metadata Plane
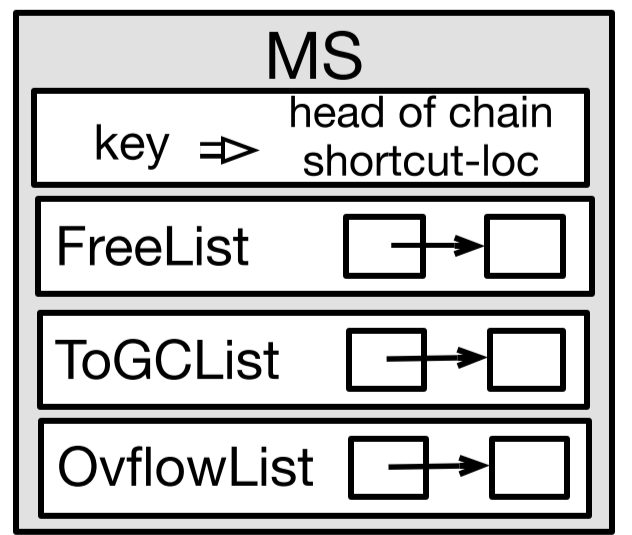
MDS负责元数据管理、空间分配、GC、负载均衡。
MDS上记录了entry的位置
GC
一个简单的方法就是,MDS上维护一个freelist。每次CN申请alloc的时候,就从freelist里划一个batch给CN。(在划分上做,load balance)
CN在后台异步做GC,把老版本数据的位置返回给MDS,MDS则把DN上老数据删除,更新header,然后把位置压入freelist,之后接着用。然后DN上的链表头结点位置也就变化到GC的位置。
Cache Invalidation
上面的做法会引发一个问题,持有被GC节点位置cache的CN,如果继续正常遍历的话,可能会找到错误的位置。
因此加了新方法来保证正确性:
- GC的时候,MDS不去清空数据
- 为每个数据区域(逻辑上)维护一个GC Version
- 当MS每次收到一个GC请求时,这些GC的对应区域被赋值自加后的版本号。
- DN上的数据也会维护版本号,CN上cache的位置也维护版本号。
- CN从DN上读取数据时,会对比版本号,如果不一样,则说明cache失效。
Read Timeout Scheme
以上的设计还不能保证read的原子性。如果read访问太长,有可能会读取到被GC后又被重新写的结点。
提出一个类似FaRM[4]里的操作。因为上述的case,需要两个RTT才能完成,一个RTT用来提交,一个RTT用来MS发布新空间。那么当read操作超过两个RTT后,就打断它。
Ovflow list
用版本号,就存在溢出的风险。尤其是RDMA verb操作大小有限制。所以CN没办法知道当前看到的DN上的版本号,是match了自己cache的,还是溢出后的。
解决方法:
- MDS维护一个Ovflow List。当MDS自加GC version发现溢出时,就把这次释放的空间,放在ovflowlist里。放在这个list里的空间,会等待一个特定时间长度$T_e$后才移入freelist。
- CN在$T_e$时间内未访问的entry上,把所有的缓存下来的位置全部删除。
- 为了同步MS和CN的时间,MS会在每个$T_e$给CN发一个包。
GC version是绑定在某一个数据区域上面的,如果被删除了,自然要去MDS上去拿,那就获得了overflow后的version,也就完成了更新。
基于以上的过期方法,CN就不会持有 有可能发生mismatch溢出后版本号的cache位置了。
最后给一个操作流程示意图作为总结。

Reliability
可靠性上,每个enrty有多个DN做replica。另外提出了一个chaining replication。
下一个version的会被存在另一个DN上。
Recovery
Data Node
transient failure
面对短时的错误,CN会直接回滚状态。比如向DN写入数据后,不能维护链表。就当做这个空间从来没写过,以后再重新写。
permanent failure
针对类似宕机之类的为题,提供了一个特殊的replica机制。
每个entry有N个指向下一个版本的指针,指向在不同DN上的多个replica。
为了能够同时更新所有replica指向下一个版本的指针:
- 写入N份新版本的数据
- CN并发地向N个老版本通过CAS请求一个标志位(if it's in the middle of a replicated write),用来标记是否可写。
- 请求成功后,并发进行修改N个指针的值。
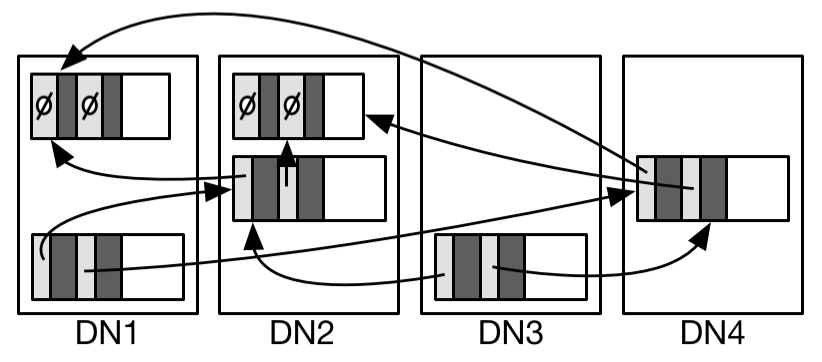
Metadata Server
MDS靠同步部分元数据(key和对应的位置)的镜像节点来保证可靠性。一旦挂了,就上镜像节点,然后镜像节点通过备份的部分元数据,重建其他元数据。
Load Balancing
设计了有两层负载均衡,一层通过MDS分配跨DN的空间来实现,一层在CN上,通过写数据到不同DN上来实现。
这部分在实验里测了几个策略。
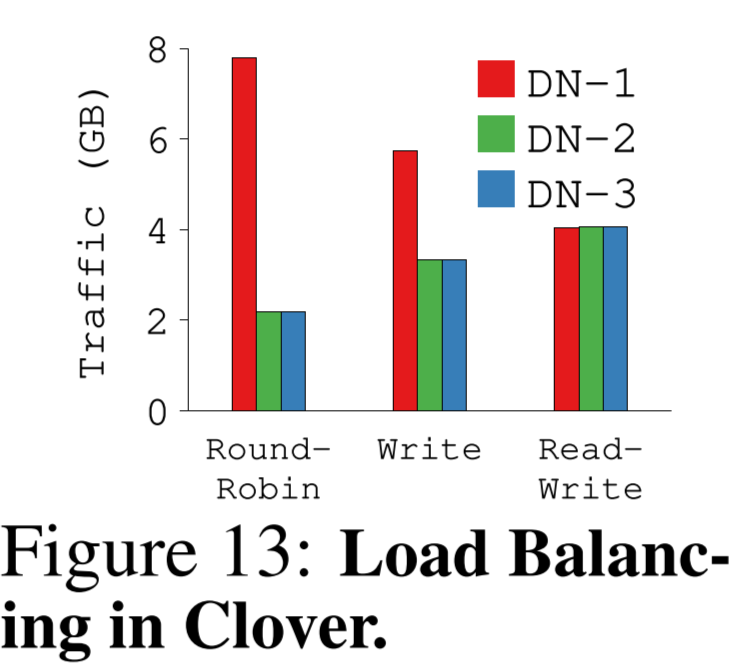
就是在最近访问的DN上写,read分配到不同的replica上,能达到完全的均衡。
Eval
config: IB集群,DRAM模拟PM。
latency
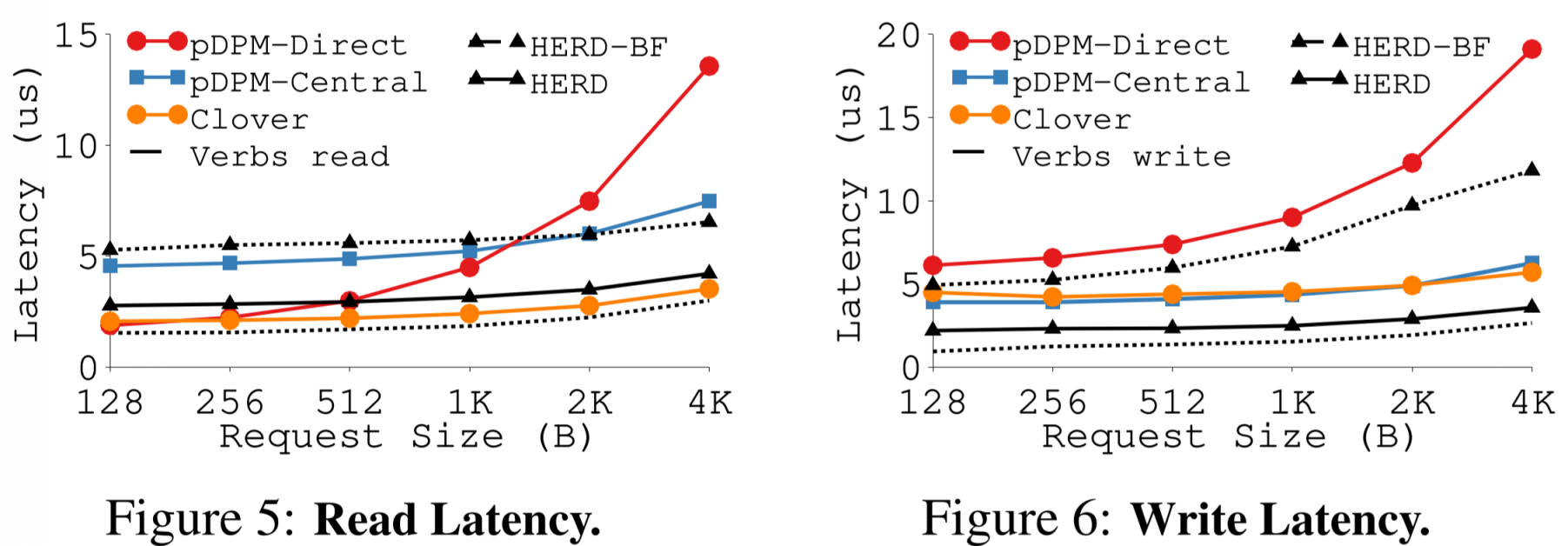 对比的HERD[3]是SIGCOMM '14的工作。
对比的HERD[3]是SIGCOMM '14的工作。
在大部分情况下,read的延迟大小就是RDMA延迟大小,write的延迟就是两倍的RDMA延迟大小。
YCSB
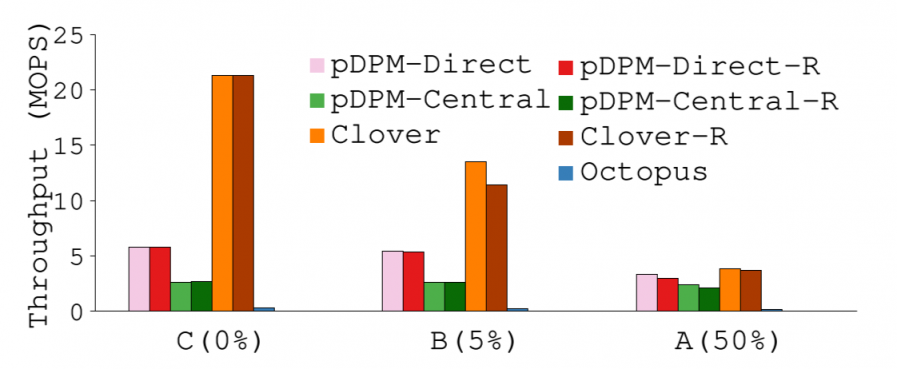 在吞吐量的指标上的对比
在吞吐量的指标上的对比
可以看到,write操作需要2 RTT的Clover在写比例上升后,性能明显下滑。到50%的比例时,99分位的操作就需要6个RTT才能完成。
Octopus表现不好,不过他也不是为了键值存储设计的,实验是在上面在跑了一层MongoDB来支持键值存储的。
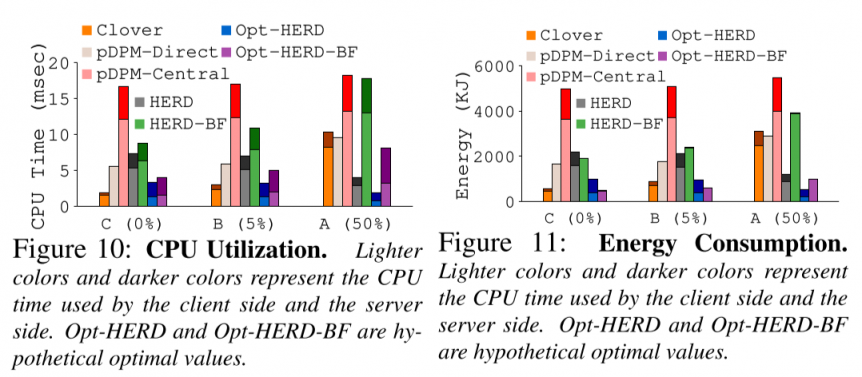 在CPU使用率、功耗等指标上,都有一定的优势。
在CPU使用率、功耗等指标上,都有一定的优势。
scalability
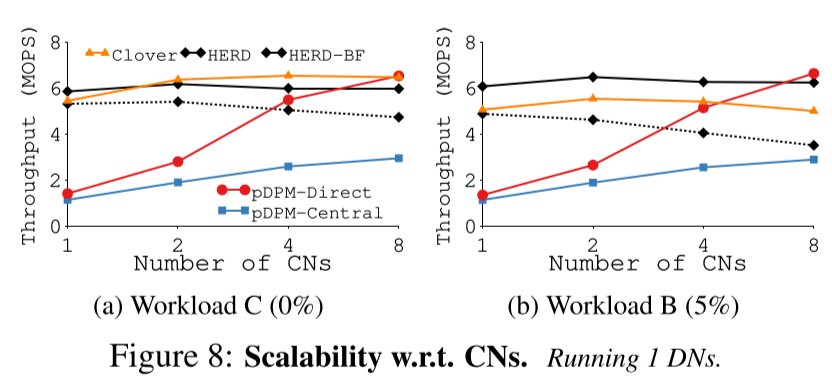 随着CN数量增加,吞吐量的变化。
随着CN数量增加,吞吐量的变化。
文章也提到,有的系统也没有专门为多线程访问设计。
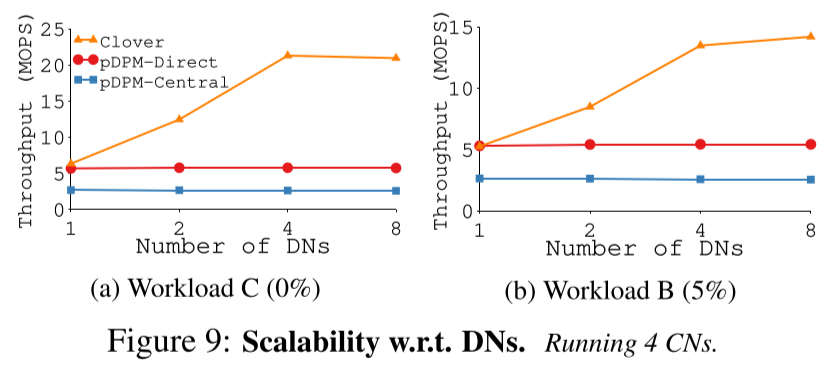 Direct受限于计算瓶颈,Central受限于coordinator瓶颈。
Direct受限于计算瓶颈,Central受限于coordinator瓶颈。
thoughts
MDS和DN分离访问路径的设计不少,如Ceph等
为了解耦,CN要做好多事情,为了GC,CN肯定要存好多old addr再发送给MDS。文章里也没交代ToGCList是干嘛用的。。
如果把这些元数据管理的放到MDS上也可以吧,等价于说把central的传数据,改成传地址就好。这样元数据管理逻辑上比较简单。但在键值存储这种小数据上,会不会类似对象存储进一步遇到MDS瓶颈的问题(实验里的zipf YCSB里,central表现的就很差)?
以及直接加入一致性哈希是不是就可以帮助这样的中心coordinator模式提升扩展性呢?
因为是模拟上做的,应该也有针对optane特性的优化空间
文章没怎么讨论load balancing策略
新加入的机器作为不平衡的角色,怎么快速参与到load balancing?
load-balancing的机制感觉有点handicraft,感觉MDS其实不需要做什么东西,FreeList顺序放就好,因为被GC得越多的,未来负载越轻。
cache replacement的策略上,用的FIFO,LRU没啥效果。不知道这个有没有可做文章的。
ref
[1] Tsai, Shin-Yeh, Yizhou Shan, and Yiying Zhang. "Disaggregating Persistent Memory and Controlling Them Remotely: An Exploration of Passive Disaggregated Key-Value Stores." 2020 USENIX Annual Technical Conference (USENIX ATC 20). 2020.
[2] USENIX ATC '20 - Disaggregating Persistent Memory and Controlling Them Remotely on youtube
[3] Kalia, Anuj, Michael Kaminsky, and David G. Andersen. "Using RDMA efficiently for key-value services." Proceedings of the 2014 ACM conference on SIGCOMM. 2014.
[4] Dragojević, Aleksandar, et al. "FaRM: Fast remote memory." 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14). 2014.