(9.29 update Octopus)在NVM上的单机存储系统有很多,如BPFS,NOVA[1],Ziggurat,FlatStore,SLM-DB,HiKV等等(可移步:Non-Volatile Main Memories File Systems系列 - nan01ab)。那么应该如何通过InfiniBand等网络的RDMA(Remote Direct Memory Access)环境来构建出分布式的NVM系统呢?类似Ceph和Gluster这样流行的系统也可以使用在RDMA+PM上,但效果并不是很好,后文将简单介绍一些相关的工作。
本文主要分享一些UCSD NVSL组的工作。
NOVA FAST '16
NOVA[1]是一个单机上针对NVM设计的日志结构文件系统。虽然只是单机的,但很多后续分布式的工作都借鉴了这个工作的思想,更是一篇高引的工作。
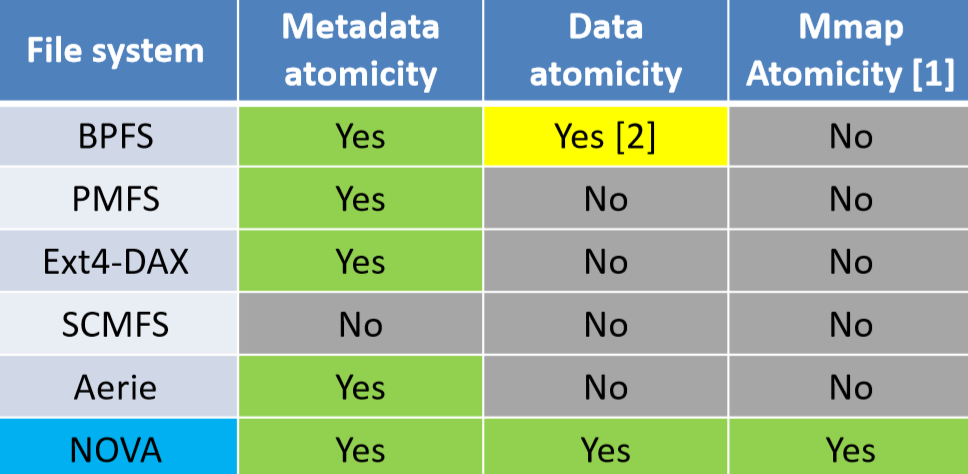
在NVM上文件系统有几个挑战:
- 性能。因为NVM在硬件上能提供高带宽和低延迟。所以在软件层面可能会有瓶颈。
- 如何使用新指令集来保证写入重排导致的一致性问题。
- NVM只能保证64bits的原子性保证,如何保障在一些比较复杂的POSIX操作(又改metadata,又改data)下的原子性。
简单介绍下NOVA的设计思路,不谈具体的细节。
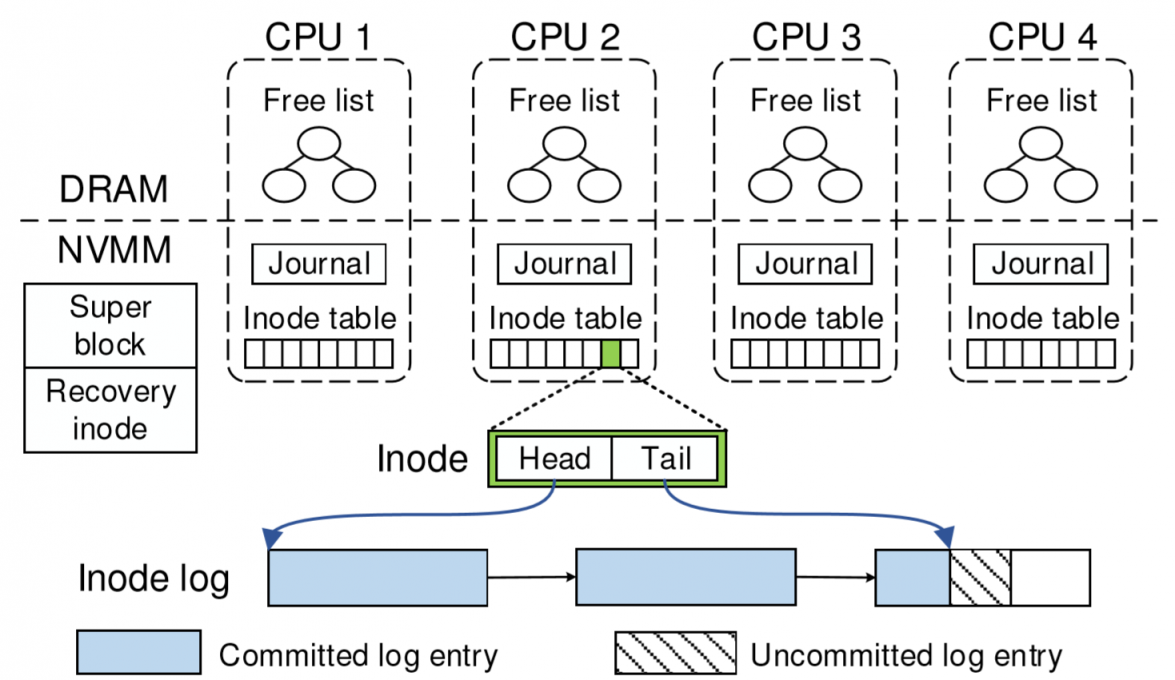 上图为NOVA的整体架构。在NOVA中,在DRAM上通过一个radix tree来维护索引(即页表),NVM来保存数据和日志。
上图为NOVA的整体架构。在NOVA中,在DRAM上通过一个radix tree来维护索引(即页表),NVM来保存数据和日志。
- 为了使用好NVM的随机读写性能,NOVA的每一个inode都使用了独立的一个log,并发上也不会存在问题。
- superblock内保存的是全局的FS信息
- 每一个CPU内维护自己分配到的inode table、journal、free list(空闲页表)。每个inode被新分配来的时候,会被轮流分配到不同的cpu上,加入所在CPU的inode table。每一个inode保存metadata,并维护一个log链表,每次从尾部添加log,这是为了recovery。链表的log降低了GC的开销,另外也是利用了NVM随机读写能力。每个CPU独立管理,可以很好地提升并发性支持,不用担心锁问题。
- 为了提供原子性支持,NOVA用了一个环形journal,用一组前后指针(<enqueue, dequeue>)。在inode更新了log后,,开始transaction把受影响的log写入到enqueue指向的位置,更新enqueue指针。等到inode的所有操作结束后,dequeue指针更新,结束transaction。如果事务失败了,就根据journal回滚。
- 在数据的组织上,用Copy-On-Write来写入数据,不log数据。以此减短log,加速recovery和GC;page管理也简单。NOVA把NVM的空间切分为pools。每一个CPU拿一个pool,如果满了就从最大的pool里再取(If no pages are available in the current CPU’s pool, NOVA allocates pages from the largest pool??)
正常关机会把分配的信息写入到recovery信息里,如果非正常关机,就遍历inode log来重建分配状态。
GC过程中,数据的page很容易判断进行回收。inode log的GC比较复杂。
定义以下状态就判定entry dead:
- write entry指向一个无效页的
- 旧的更新metadata的(后面有个更新的
- 现在已经被删除的文件对应的以前创建的
NOVA提供了两种GC,第一种,Fast GC就是直接回收一个log page里全dead了的对应的指针。
当过半的log entries dead,就启动thorough GC,做拷贝回收。
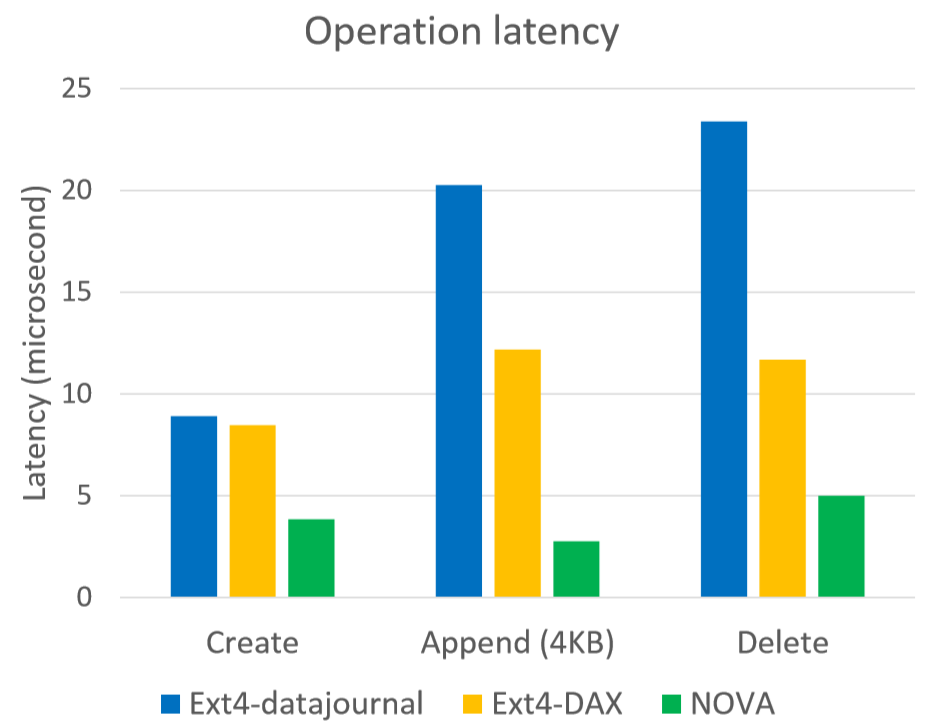
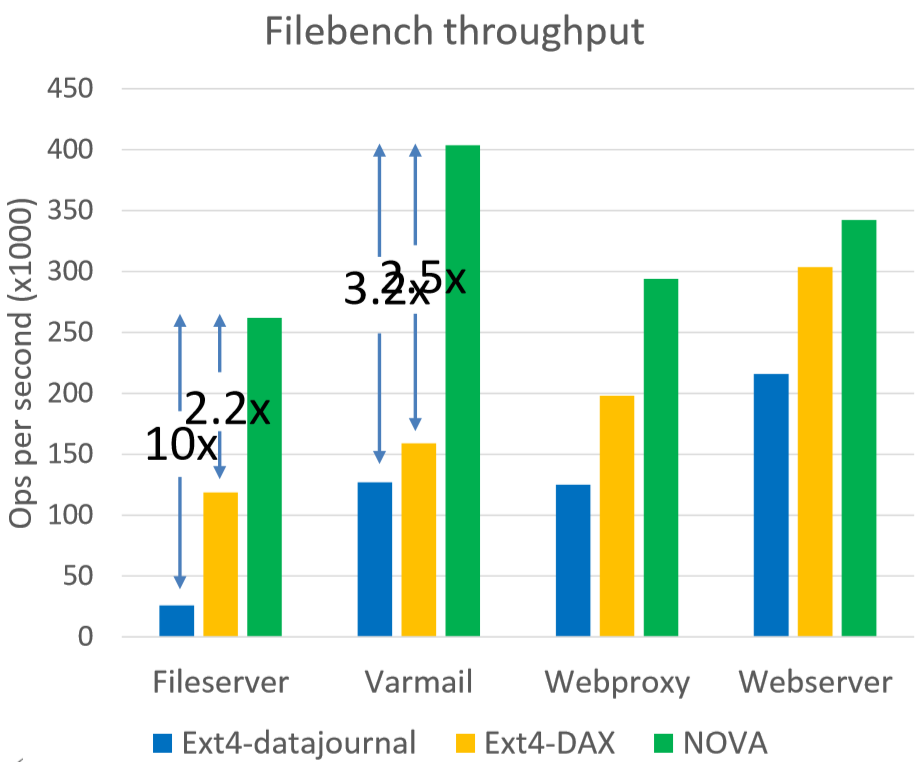
实验在Intel PM Emulation Platform上和传统的一些文件系统进行比较:
开源于Github
Mojim ASPLOS '15
Mojim[2]在单机上提出了一个多层结构来实现副本策略。第一层包含了两个主从节点(主节点+镜像节点),可选的第二层包含了一个或多个的二级备份节点提供弱一致性的read访问。向上为应用(如PMFS)提供存储接口。
镜像节点通过RDMA从主节点中复制数据,备份节点则从镜像节点中复制数据。nvm FS里文件对应的page绕过kernel cache,直接对应到NVM上的地址,然后DAX。
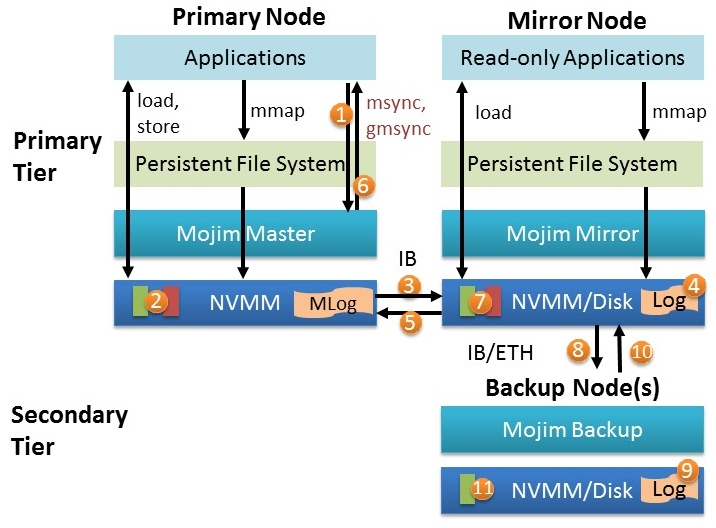
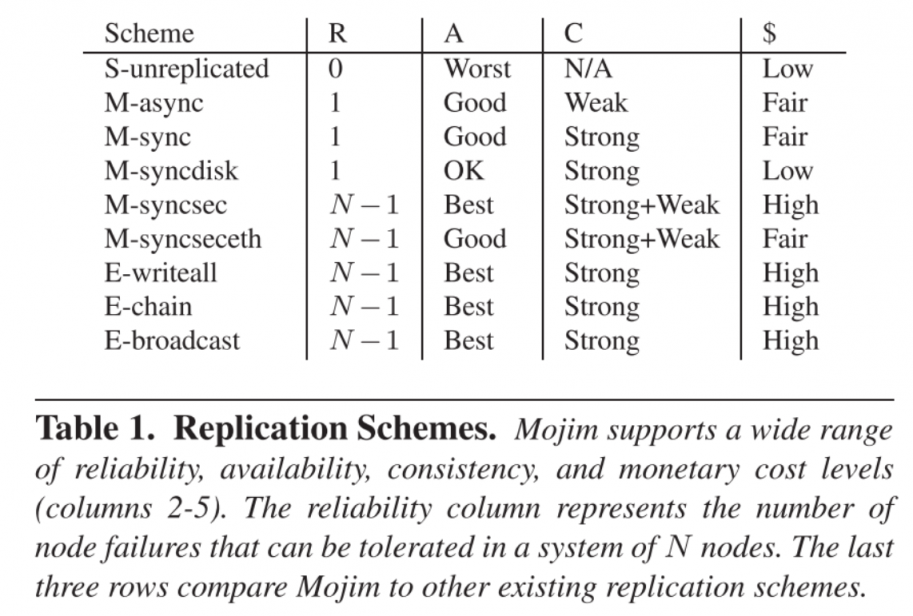
同时Mojim给了一些多样性的副本策略供选择。
Orion FAST '19
Orion[3]现在还是FAST19目前最多被引用的文章。Orion在核心态上做一个文件系统,向下融合本地NVM和远端NVM(即综合DAX和RDMA),向上为应用提供POSIX接口。通过简化结构(整合文件系统和网络层),减少flush、数据迁移的开销
old:

Orion:

Orion的基础结构如下图
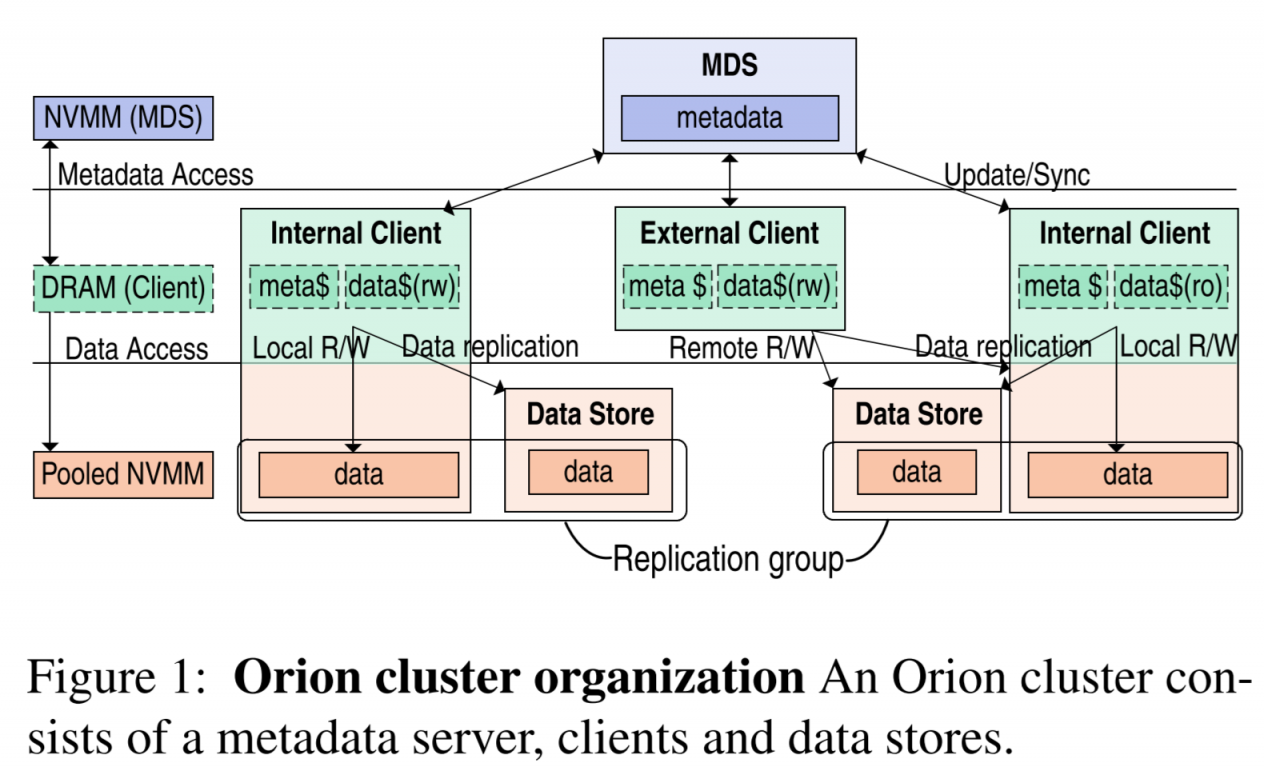
文章大部分的内容用来探讨Orion的内部通信机制设计。
MDS(metadata server)和DS(data store)都通过replica来保证availability。Internal Client指带local NVM的client,也分担一部分存储数据的任务。External就是没有local NVM的,只是一个单纯的客户端。client会和MDS做双向的通信,client只会从DS单向拿数据。
在数据的获取上,维护一个Globally addressed pages来索引数据页。
Orion用了NOVA[1]的思想,使用atomic append的per-inode log,在MDS上每个inode都持有log(记录针对这个inode的操作),可以更好的并发处理元数据。每一个client对于打开过的文件,保存一份inode和它对应log的副本(在和MDS通讯时边做更新)。这份日志副本将会被用来文件元数据恢复、检测本地文件版本。【inode就是文件的元数据】
在数据的分配上,MDS只负责将大块的数据范围指定分给Client,内部的数据如何使用则由client自行分配。
在RDMA上实现一个强一致性的系统是有挑战的,因为RDMA并没有提供标准的进制来实现在远端NVM上的强制写入。
client写入时是在逻辑上属于自己的page(client-owned pages)上做Copy On Write by RDMA or DAX,然后加log到local的inode,最后再更新到MDS。
提出了一个轻量操作Tailcheck。这个操作是client发起用来检查对比client和MDS的log长度是否匹配。不匹配则进行传输日志,然后把本地的copy做更新。
client在每次读取前,先做一个tailcheck,看看MDS是不是做更新了。然后可以从inode上获得远端DS的一个页地址,然后RDMA取回到自己的DRAM cache上。这样未来的读会命中本地DRAM,写也可以去本地的NVM。
client arbitration保证数据的persistence。这个操作的优越性基于以下观察:
- RDMA inbound操作(NIC可以独立完成)非常轻量
- 小操作可以有更少的transaction,更低的延迟。
- MDS的CPU资源很宝贵,浪费会直接影响系统速度。
这个操作指的是在并发更新MDS上某一个inode的时候,客户端先进行tailcheck,如果是最新的才可以commit,不是就需要先阻塞并更新本地的log,然后再发起请求。【注意Orion基于RDMA网络的可靠性,不考虑网络丢包】
基于以上可以实现对元数据的一致性。可选的,为了性能放松一致性引入Speculative log commit,client在确定数据写入到DS前,就可以向MDS发起log commit请求。
实验结果
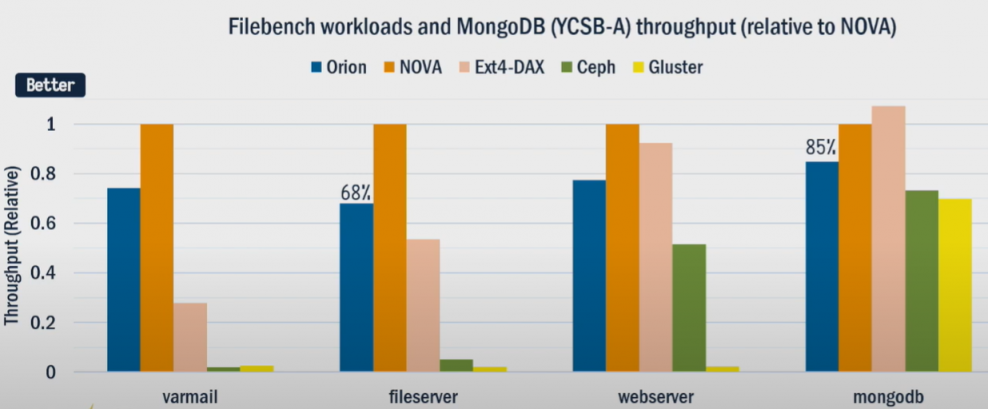
吞吐量上能达到68%~85%的单机系统NOVA的水平。
FileMR NSDI '20
本文[5]优化通过RDMA远程访问NVM File System的场景。对RDMA一知半解,仅做笔记,不少细节不太理解。
story:RDMA被用在分布式部署NVM上,相比TCP/IP可以提供高带宽低延迟。但RDMA并非为NVM、FS设计,在处理一些传统文件系统的功能需求时存在许多缺陷,比如不能碎片整理、append、大文件性能差。同时RDMA和现有的部署在其上的NVM FS很多功能是存在重复开销的、甚至是不匹配的(translation)。
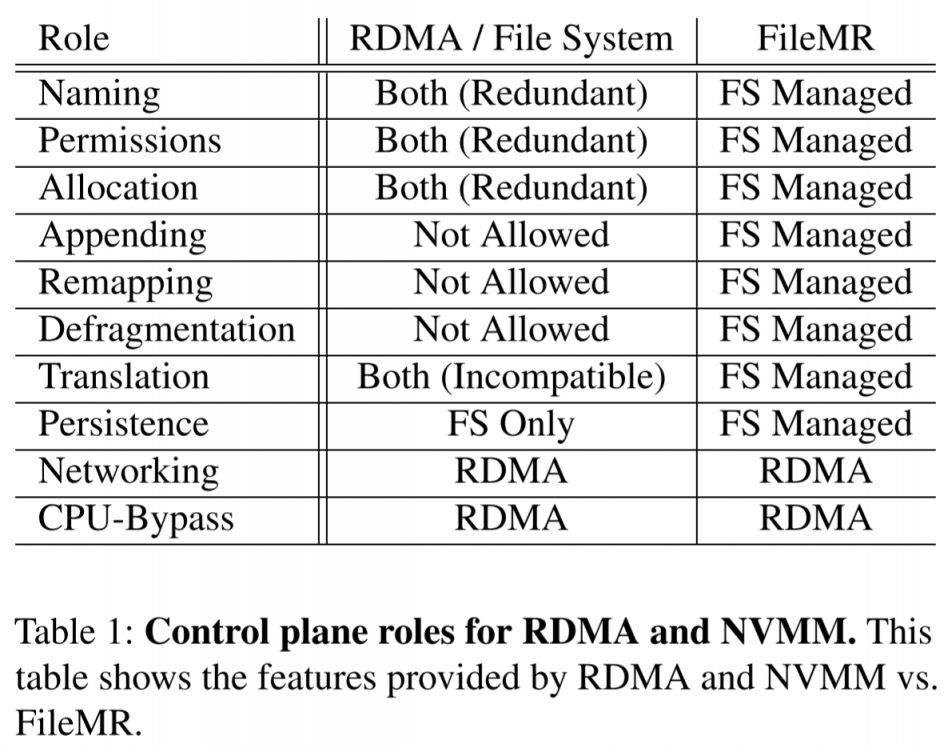
另外的一个问题是当访问的region size越大,cache命中率会严重下降,导致吞吐量的明显下 降。
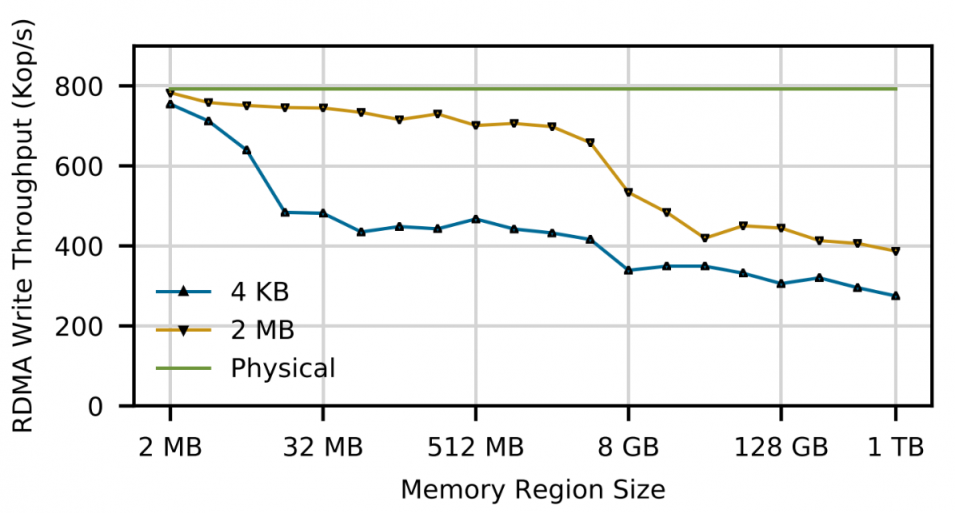
作者提出的FileMR是一个RDMA的memory region,也是一个NVM上的文件,从而进行一定程度的整合。对RDMA原有的memory region进行了一些扩展,来对NVM提供一些基于文件的接口。相当于把原来重复的一些功能放到了FS来做,也降低NIC的负载。
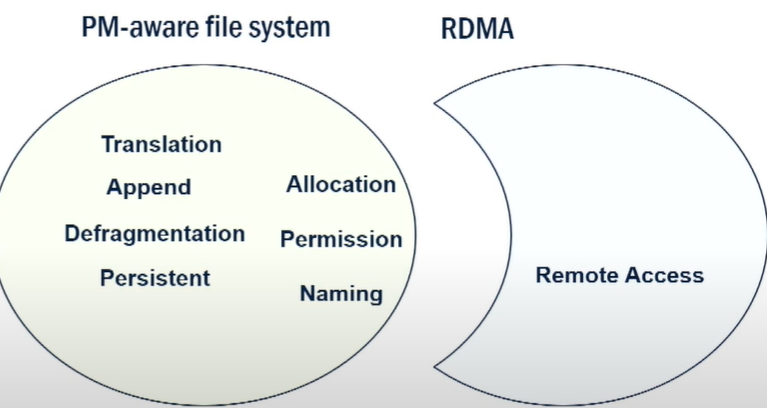
FileMR的设计:
- merged control plane:client通过file offset来定位内存,而不是使用虚拟或物理地址。FileMR利用文件来作为RDMA的memory region,能提供naming, permission等支持。
- RangeMTT: ranged-based address translation:FileMR的translation不再是基于page,而是基于一个范围,这样的方法有利于创建管理一些大的线性空间。
- B树索引结构,每个entries通过offset来索引,从而映射更大的空间。
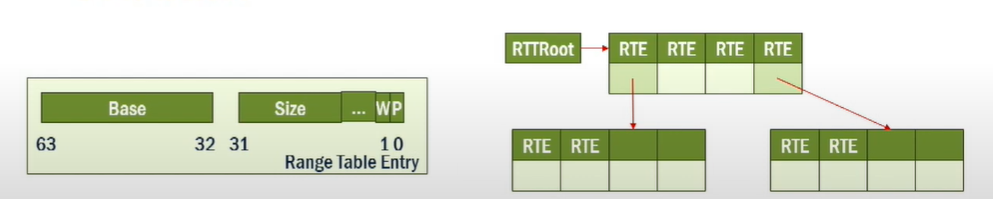
- 因为文件是在连续的空间上组织的,所以这是的RDMA NIC的pin-down cache寻址可以更节约空间。
- B树索引结构,每个entries通过offset来索引,从而映射更大的空间。
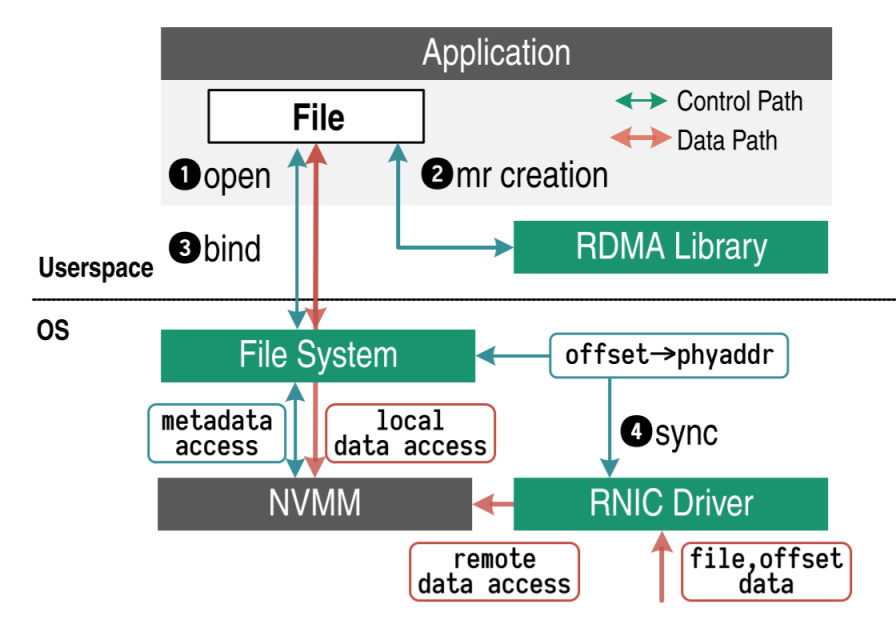
如图所示为逻辑层关系
- 创建一个FileMR前,先open一个备份文件。
- 创建一个FileMR
- 绑定FileMR到一个文件上。至此完成了region的初始化,产生了一个filekey,用来给远端的client进行访问。
- FS让FileMR的地址信息和RNIC同步
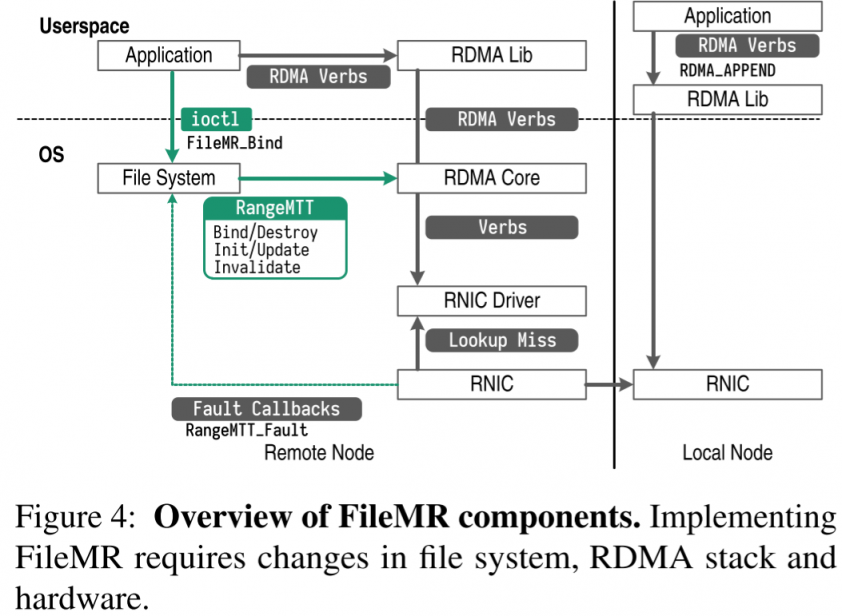
当client的请求来到时,NIC通过给定的fileMR和offset,加上FS的信息转译得到物理地址。另外地,FileMR提供了一个新的append指令来增大region,server会更新FileMR的大小。【有一个trick防止失败的append,不赘述】
FileMR的几个优点:
- 减少了NIC上的translation开销,也提升了NIC上cache的命中率。
- 使用FS上的访问控制来简化原有的RDMA上的内存保护机制(RDMA用一组32位key来做memory regions的访问控制)。
- 用持久化文件来实现连接控制,简化原有RDMA的ephemeral memory region IDs
- 远端的mem可以直接移除或扩张而不需要取消原来的权限或者关闭连接。从而使FS可以做碎片整理或做append等(RDMA无法实现的一些feature)。
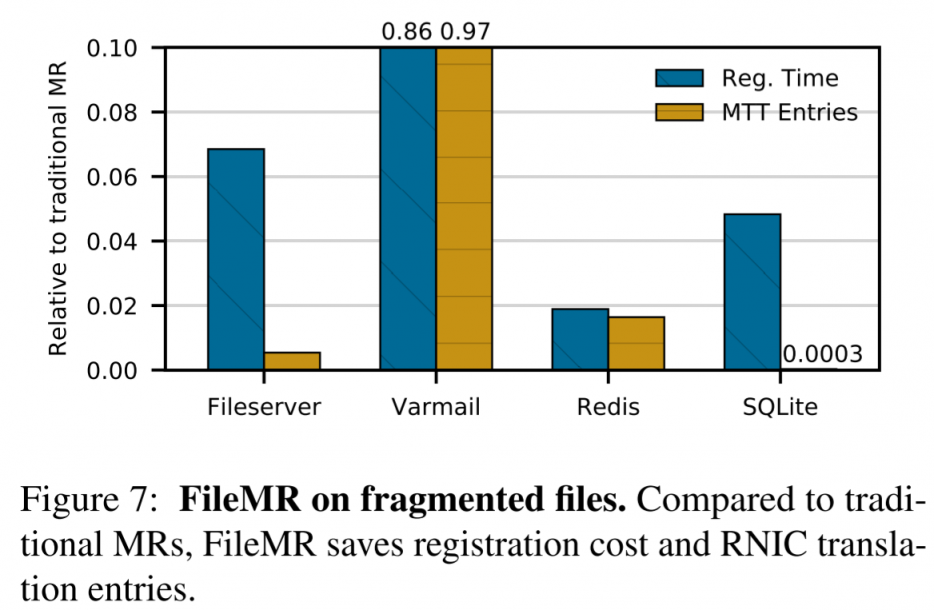
实验latency对比,在模拟平台做的。
AsymNVM ASPLOS '20
problem: 单机上NVM的容量大,资源利用率比较低,怎么让多机通过RDMA分享这个NVM存储,实现一定程度的运算和存储解耦。另一个问题是RDMA的延迟相比NVM还是很高。
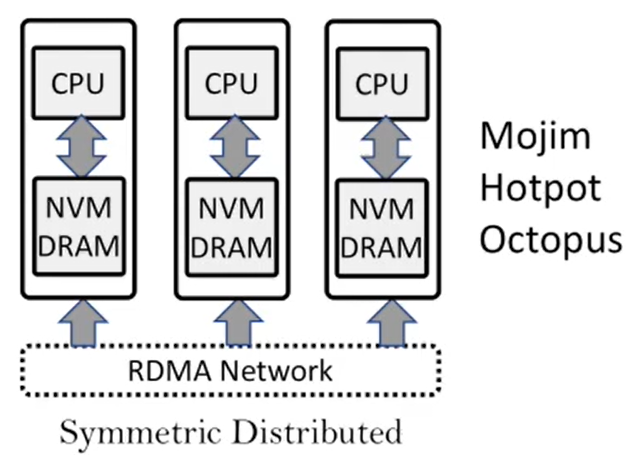
作者认为以前的工作,如上图,都是对称的,即每个node都持有相同的RAM、NVM,而AsymNVM[7]提出了非对称的方式,进行一定程度的disaggregation,提高scalability。另外通过分离数据和log的方法来隐藏延迟。
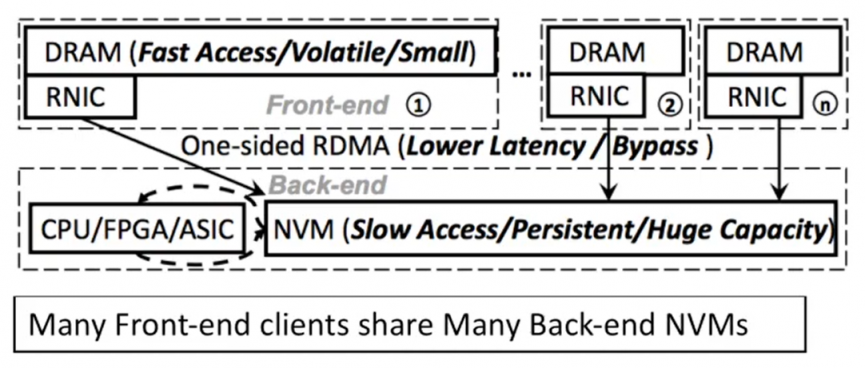
如上图,前端的机器只有DRAM,通过RDMA NIC来和后端的NVM节点通信
AsymNVM上有两种log,一是mem log,记录每次mem单位上的操作,用来做transaction的replay。二是operation log,记录数据结构语义上的改变,用于recovery。
transaction的实现上,rnvm_tx_write通过RDMA_Write一次性写入多个mem_log来保证事务的原子性。这样就降低了网络通信的开销,分离了data和log的传输后,也变相降低了延迟。
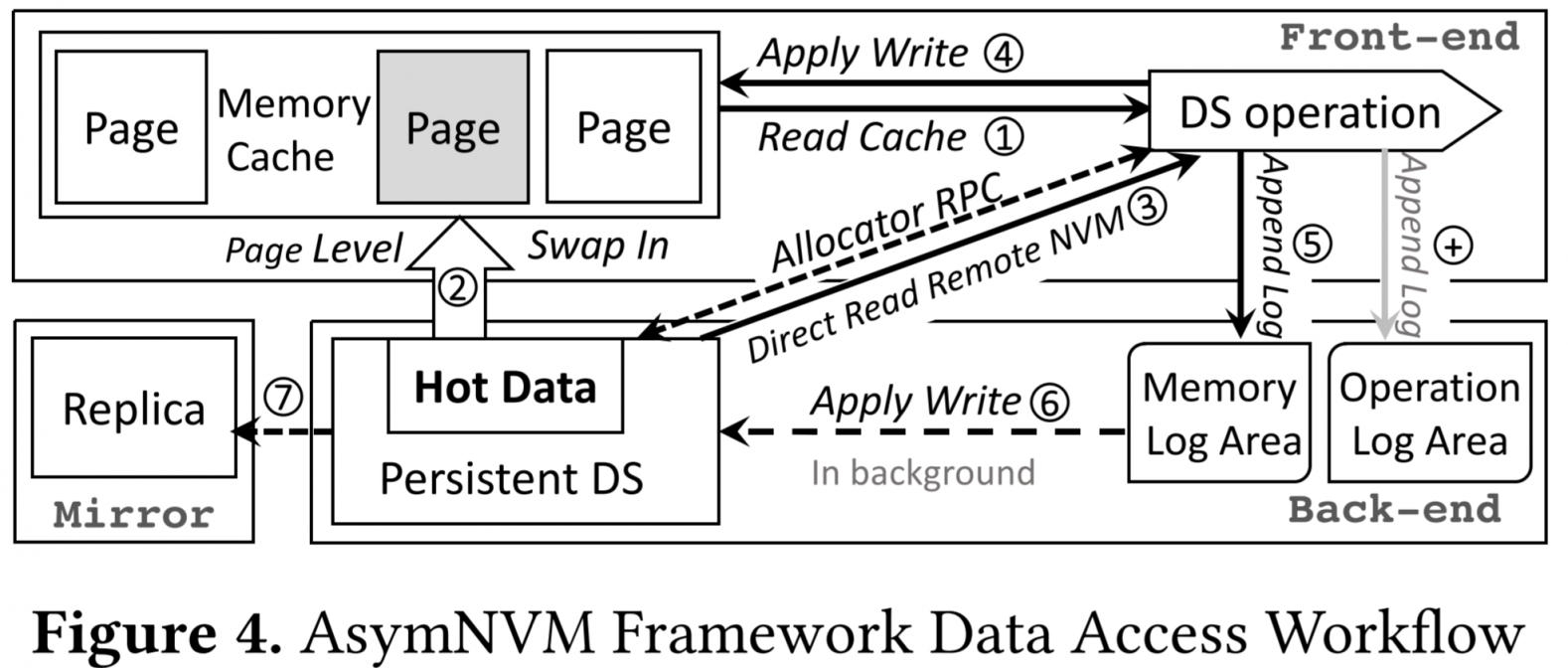
如上图所示,为AsymNVM的workflow。
- Gather阶段
- cache命中就直接读取cache(1)
- 不命中则根据冷热来执行swap(2)或直接读取远端RDMA(3)
- Apply阶段
- op log刷到NVM上(+)
- 执行op log的操作
- 把一个batch的mem log刷到NVM上(5)
- NVM执行mem log的操作(6)
- NVM节点把log复制到mirror node上(7)
- 更新cache(4)
data management
front-end
cache用hashmap来映射NVM上的地址到DRAM上的地址。缓存替换算法上,先随机pick一个page集合,然后在这个集合里找最近用过的。
针对RAM上空间,使用slab切片,分成full, partial, empty三个list来进行管理。根据Best-fit来从partial list中选择进行存放。满了才通过RPC来allocate新的。
定期会释放free blocks(数量超出阈值)。
back-end
后端的NVM节点用bitmap记录NVM使用情况。
metadata也存在前端、后端都可见的地方上(well known location)。重要的metadata会存在NVM上做备份,这部分metadata也是通过hashmap来找位置。
concurrent
在并发设计上,针对单写多读场景,写操作是排他的。在数据结构上,构建了lock-based和lock-free两种,按需选择。
- lock-based:直接上RDMA CAP锁。read需要多次retry,但优化了write。
- lock-free:需要复制出多份的数据,做path copy update(append-only B Tree)。优化了read,降低write的效率。
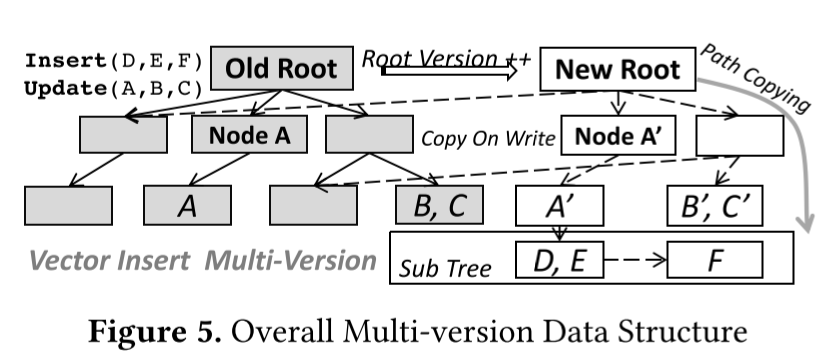
Recovery
至少有一个带非易失设备的mirror node做备份,后台自己同步(不在访问路径上)。可以多个后端节点共用一个mirror node。如果后端节点挂了,有NVM的mirror node可以升级为back-end承担访问。另外AsymNVM也通过租约、voting的机制来保证一致性。
Octopus ATC '17
Octopus是一篇清华的工作,也开源在Github。
这篇文章想要做的事情是,CPU的负载太大,如何用好RDMA one side verbs来改进网络通信过程,降低CPU负载,拉高指标。
High Throughput Data I/O
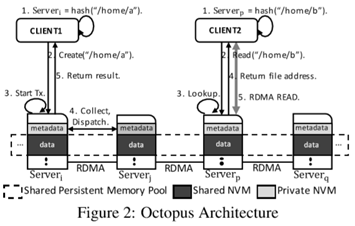
如上图所示,为Octopus的基本架构,client为FS的机器,后端的server为都有NVM的机器,把所有NVM抽象为一个Shared Persistent Memory Pool。
- Shared Persistent Memory Pool
- 在pool内寻址的操作都是通过文件名,进行一致性哈希找到对应的实体机器节点
- 在数据传输中,数据直接通过file sys到NIC,绕过user space。减少了数据复制的次数。
- Client-active data I/O
- client active区别于server active,在通信中减轻了server的负担。server在发送recv包时,不需要带上mem上的数据,而只传输mem addr。然后client通过RDMA read绕过server cpu直接读取。
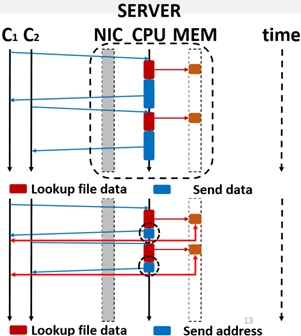
- Rebalance CPU/Network overhead
- client active区别于server active,在通信中减轻了server的负担。server在发送recv包时,不需要带上mem上的数据,而只传输mem addr。然后client通过RDMA read绕过server cpu直接读取。
Low latency Metadata Access
- Self-identified metadata RPC
- 传统的RPC通信时,需要把msg放在包里,通信上的开销比较大。一个简单的利用RDMA单向verb的方法是,写入到server mem的buffer上,然后server cpu在buffer上scan。这样的问题就是,CPU老是去scan还是有cpu上的瓶颈
- 所以self-indentified metadata RPC就用RDMA_WIRTE_WITH_IMM,就还是一个单向的write操作,但是带了一个immediate field,记录了写入数据的位置,server就可以直接知道msg存在了本地mem的什么位置,避免了scan的开销。
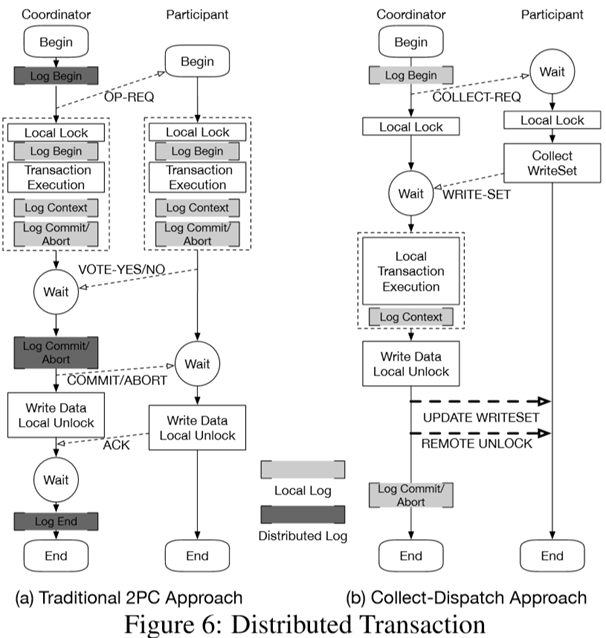
- Collect-dispatch transaction (Distributed Transaction)
- 2PC(Two-phase commit)需要在coordinator和participant中有比较多的通信过程,有两次双向的RPC,开销大。
- Octopus给出了一个在coordinator本地做logging的分布式事务策略,然后coordinator直接RDMA单向写入到participant的mem上。这样两次双向的RPC通信,变为了1次双向RPC和两次RDMA单向verb。
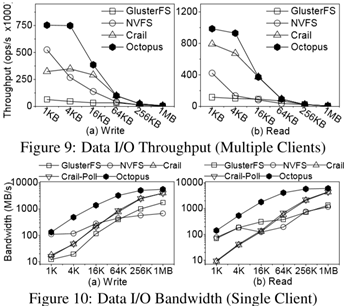
实验结果如下:
Ref
[1] Xu, Jian, and Steven Swanson. "NOVA: A log-structured file system for hybrid volatile/non-volatile main memories." 14th USENIX Conference on File and Storage Technologies. 2016.
[2] Zhang, Yiying, et al. "Mojim: A reliable and highly-available non-volatile memory system." Proceedings of the Twentieth International Conference on Architectural Support for Programming Languages and Operating Systems. 2015.
[3] Yang, Jian, Joseph Izraelevitz, and Steven Swanson. "Orion: A distributed file system for non-volatile main memory and RDMA-capable networks." 17th USENIX Conference on File and Storage Technologies (FAST 19). 2019.
[4] Orion Pre FAST 19 on youtube
[5] Yang, Jian, Joseph Izraelevitz, and Steven Swanson. "FileMR: Rethinking RDMA Networking for Scalable Persistent Memory." 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20). 2020.
[7] Ma, Teng, et al. "AsymNVM: An Efficient Framework for Implementing Persistent Data Structures on Asymmetric NVM Architecture." Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 2020. (ASPLOS '20)
[8] ASPLOS'20 - Session 9A - AsymNVM on Youtube
[9] Lu, Youyou, et al. "Octopus: an rdma-enabled distributed persistent memory file system." 2017 USENIX Annual Technical Conference (USENIX ATC 17). 2017.
附录 Optane的一些特性 FAST 20
Yang, Jian, et al. "An empirical guide to the behavior and use of scalable persistent memory." 18th USENIX Conference on File and Storage Technologies (FAST 20). 2020.
- The read latency of random Optane DC memory loads is 305 ns This latency is about 3× slower than local DRAM
- Optane DC memory latency is significantly better (2×) when accessed in a sequential pattern. This result indicates that Optane DC PMMs merge adjacent requests into a single 256 byte access
- Our six interleaved Optane DC PMMs’ maximum read bandwidth is 39.4 GB/sec, and their maximum write bandwidth is 13.9 GB/sec. This experiment utilizes our six interleaved Optane DC PMMs, so accesses are spread across the devices
- Optane DC reads scale with thread count; whereas writes do not. Optane DC memory bandwidth scales with thread count, achieving maximum throughput at 17 threads. However, four threads are enough to saturate Optane DC memory write bandwidth
- The application-level Optane DC bandwidth is affected by access size. To fully utilize the Optane DC device bandwidth, 256 byte or larger accesses are preferred
- Optane DC is more affected than DRAM by access patterns. Optane DC memory is vulnerable to workloads with mixed reads and writes
- Optane DC bandwidth is significantly higher (4×) when accessed in a sequential pattern. This result indicates that Optane DC PMMs contain access to merging logic to merge overlapping memory requests — merged, sequential, accesses do not pay the write amplification cost associated with the NVDIMM's 256 byte access size