PM+KVS+Log。舒老师组的工作,FlatStore提出了一个新的Persistent Memory上KV store的优化方案。通过对PM硬件粒度的完全利用,来提升throughput。
motivation:高并发下顺序写和随机写的BW接近。read afte clwb+fence会被block。
这俩观察都是这个工作第一个提出来的。但……
PM的bandwidth带宽有256B,老是写小键值数据就没办法完全利用。所以很自然一个想法就是把index放在DRAM上,数据的维护用log structure + batch write的方式来提升带宽【类似的,在HDD、SSD上这种粒度更大的,也使用这样的方法来利用带宽】。
log design
每个log entry的结构是
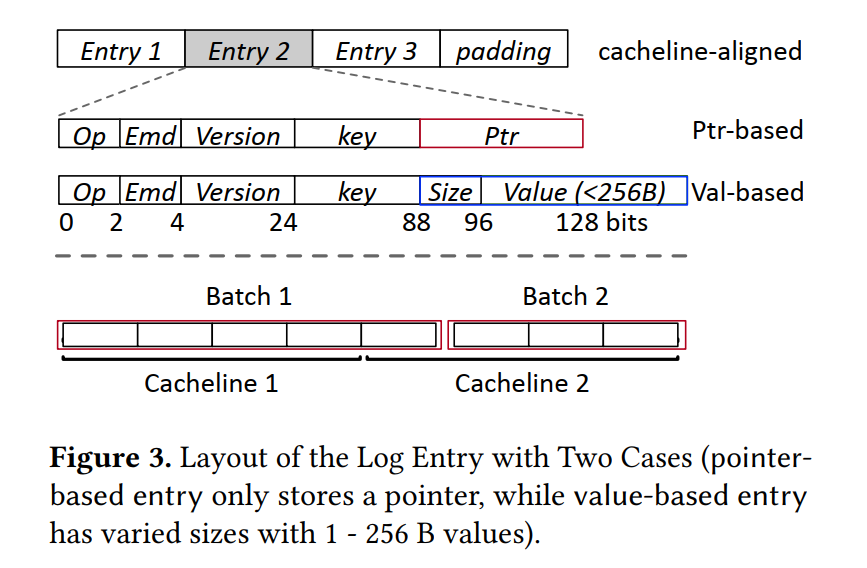
- 首先KV可以做分离【此处出现8B key原子写trick】,值小于256B就inline【这不就不对齐了?】
- version是给GC用的
- 日志是per-core的,所以好scale
- index其实不太重要,放DRAM,crash就重建,要scan就tree index(check HashKV)
- 因为len强制256B了,所以这里的ptr后8bit都没信息,删掉做compact。【default应是8B?】
- log entry做cacheline对齐+padding
entry压得有够小。。
flush design
但是如果直接用batch(指单核上,vertical),因为batching会有queue latency。所以本文最中心的方法论就是,跨多核并行(horizontal)的实现batch flush:
leader core可以在获得了lock之后,从其他核心的log queue上获得log压入自己的queue,然后做batch flush。
Pipelined Horizontal Batching的示意图
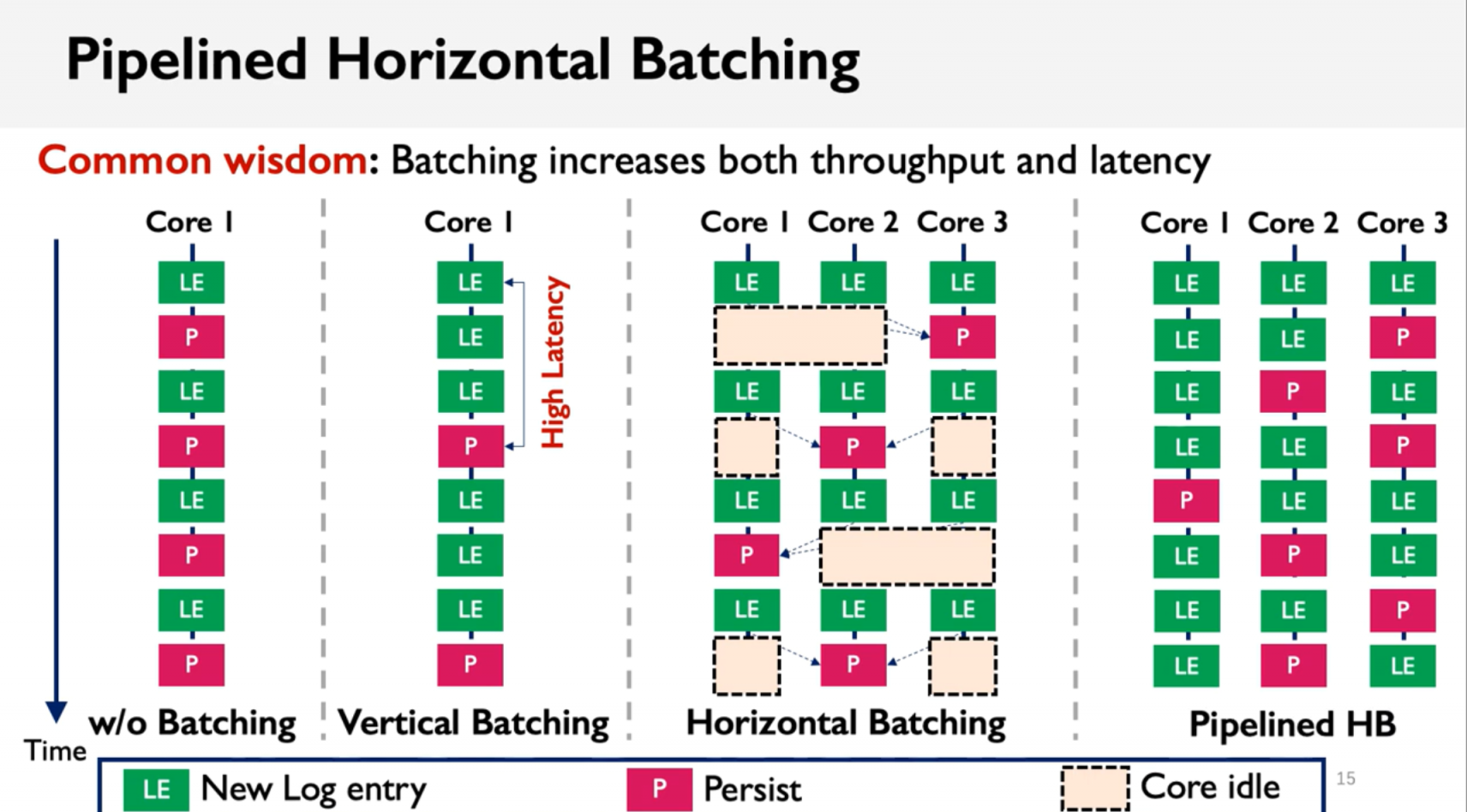
第一列是每次写log后直接flush,第二列是单核上做batch flush,第三列是有核心等待的horizontal batch,第四列是通过锁避免核心等待的pipelined horizontal batch。
如果CPU核心数太多,但单个batch(256B)还是最多放16个entries,就引入grouping分组的策略,组内内部做pipelined horizontal batch。
和代理线程做flush的区别?
然后,PM的allocator也通过log来实现异地value空间metadata的lazy-persist,因为log entry里的ptr就能证明这个空间是valid的:
- 从 Lazy-persist Allocator 分配对应保存 value 的空间,并写入数据,然后将这些数据持久化;
- 持久化log entry,记录下这个操作和之前写入的数据的信息。然后写入log,确保持久化之后更新log的tail信息;
- 更新内存中的 index。
experiments
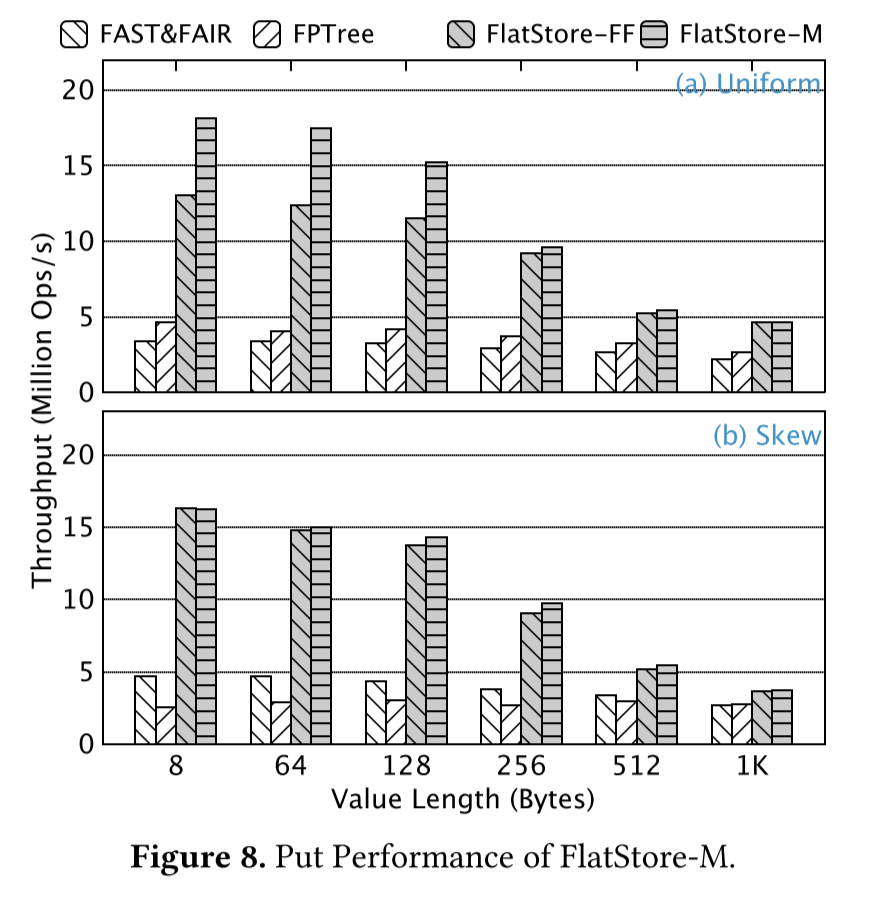
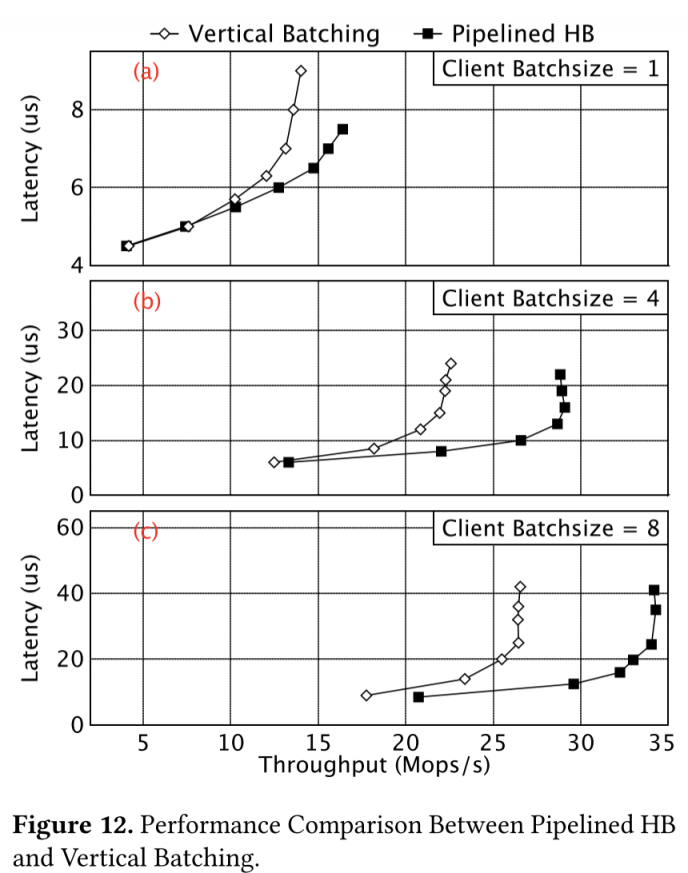 感觉是不是缺一个和无batch直接写入的latency/throughput对比?
感觉是不是缺一个和无batch直接写入的latency/throughput对比?
Ref
[1] Chen, Youmin, et al. "FlatStore: An Efficient Log-Structured Key-Value Storage Engine for Persistent Memory." Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 2020.
[2] Several Papers about KV Stores(2) from nan01ab
[3] ASPLOS'20 - Session 12A - FlatStore: An Efficient Log-Structured Key-Value Storage Engine for Persis on Youtube