Problems
上文讲到的WiscKey提出的Key Value Seperation的思路在许多现代DB中都得到了比较好的应用,TiDB, PebblesDB等等。WiscKey仍然存在一些问题,比如虽然消除了compaction时的写放大,但引入了:
- GC时移动冷数据的写放大
- 在校验key的时候也存在遍历LSM-Tree的开销。
- 因为GC的时候冷数据一直插入到LSM-Tree的高层,破坏了LSM-Tree的locality,query的速度受影响
Idea
- 基于hash来进行data grouping:通过hash分组来将相同key的update分到相同的bucket中
- 动态的空间分配:在disk上分出多个segment来实现
- 基于统计信息来判断数据冷热:冷数据减少GC次数或直接放入非segment的disk区域。
- 选择性的KV分离:小value的数据直接存在LSM-Tree,不做分离
感觉最核心的想法是切块来防止在环形Value Log上做GC的放大问题,更换GC方式来保持时序进而方便校验合法key,其他只是一些在这个上面的很自然的优化思路。
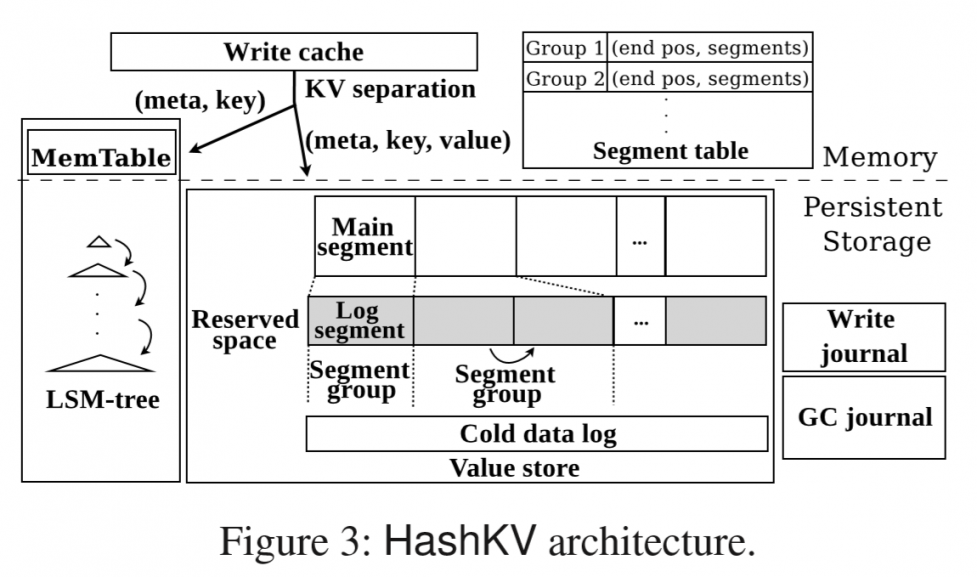
如图所示,为HashKV的架构示意图,在内存层上维护一个Write Cache和一个Segment Table。切了Segment的问题就是写入也变成了随机。之前在WiscKey中顺序读变成随机读时,提出的解决方法是多线程进行预读来利用SSD的并行性。同样的,作者希望通过write cache来进行并发批写入,同时利用cache来抵消一部分更新过于频繁,频繁到还没flush就刷新的数据。Segment Table是用来存Disk上各个Segment的位置的。
Disk内除了LSM-Tree的SSTable以外,维护包括Segment Group和Cold data log在内的Value store。还有与consistency相关的两个journal。
插入数据 Insert/Update
每次插入的时候,数据先被写入write cache,或更新write cache中的已有key,等到满后做flush。
flush时,(meta, key)写入LSM-Tree(memtable+sstable),把(meta, key, value)写入到hash得到的某一个main segment中,如果main segment满了,就类似拉链法地写入到对应的log segment中。注意这里每个bucket对应的segment是可以动态增加的。
拿到key了就可以通过hash来得到数据的位置,写的时候不需要去query LSM-Tree。LSM-Tree事实上只是在range scan的时候使用。
GC
在GC的时候,HashKV先选取一个insert/update最多的group(bucket,也就是一个main segment和对应的N个log segment)。
从这个group里面选出valid data,由于写入的时候是有时序信息的,直接从后往前遍历一遍就行,不需要再去query LSM-Tree。把valid data再写到同一个group中。
最后释放掉unused log segment,更新LSM-Tree里的地址。
冷热数据 Hotness Awareness
区分对待冷热数据的逻辑比较暴力,就是另外统计每个key的更新次数如果在GC的时候,发现某个数据没有被更新过,就挪到一个类似WiscKey的环形vLog里去。这个vLog也会做WiscKey式的GC。
再通过flag(tagging)来把更新过的冷数据在GC时刷回对应的group中。
实验
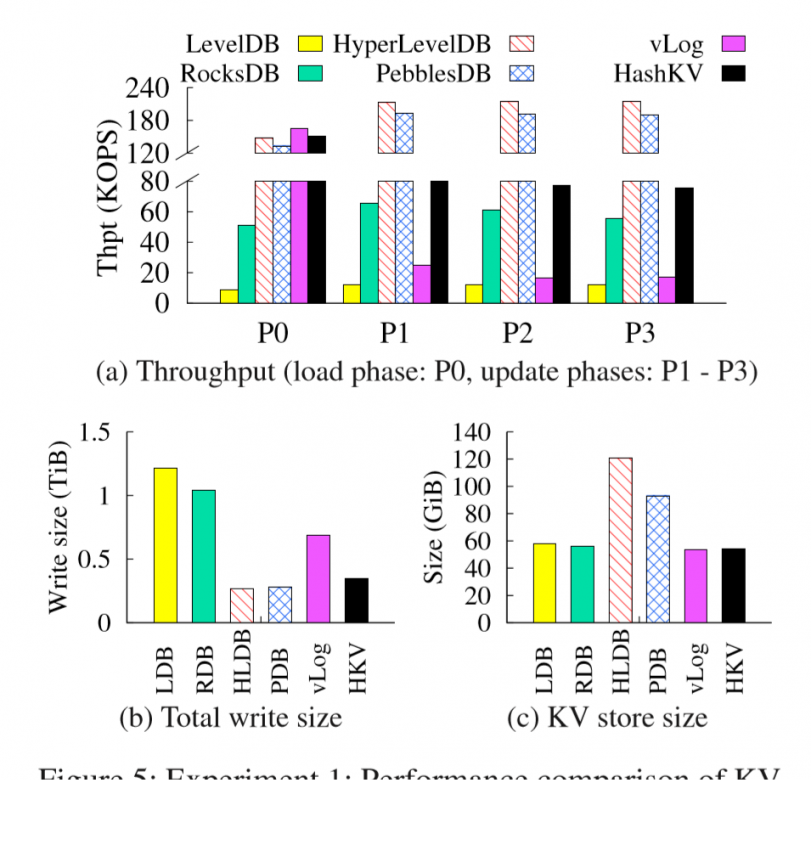
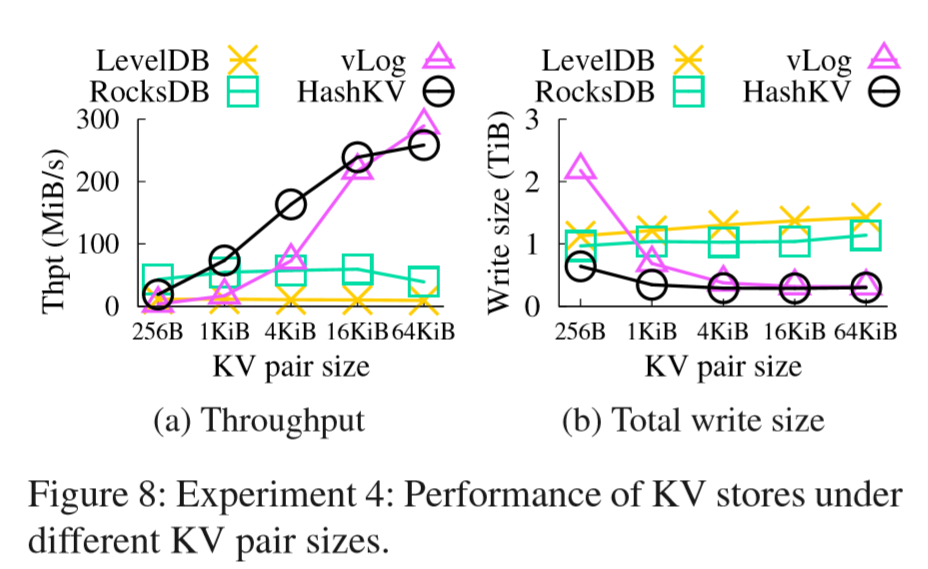
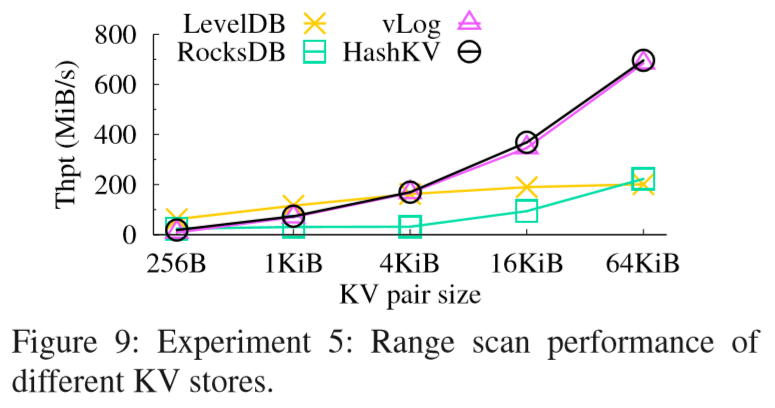
相对vLog(WiscKey)来说,确实降低了写放大。读写性能在图上看不出来有劣势。但论坛上也有人说读和scan的性能还是不如WiscKey。
想法
hash操作在这里扮演的角色不强,感觉就是强行想这样分bucket。不知道能不能换成LSH之类的东西,来帮助近的数据分布在靠近的地方,提升下locality。
另外感觉用统计信息做hotness预测可以有更好更全面的方法。ML启动!
有人说用cache做batch write会影响并行性,不太了解,不表。但感觉上cache本身就是一个非常通用的方案,不算新
参考资料
【Paper Reading】HashKV: Enabling Efficient Updates in KV Storage via Hashing,