Problem
写密集负载的键值存储已经成为一个非常重要与实际的需求,传统的硬盘组织文件数据结构B+ Tree在这个场景下存在很多问题。其中对性能最大的影响就是因为新数据插入树后,节点进行分裂,逻辑上连续的数据在物理块区上不连续,从而造成了大量的随机I/O操作,又由于硬盘的物理特性(尤其是HDD的磁头运动,需要寻柱面、寻磁道等耗时的物理运动操作),随机I/O的速度差距相对顺序慢很多(over 100x on HDD)。
Log Structured-Merge Tree
BigTable中的LSM提供了一种数据结构组织的思想,将随机I/O转化为顺序I/O,从而提升存储的效率。
顾名思义,就是日志结构归并树
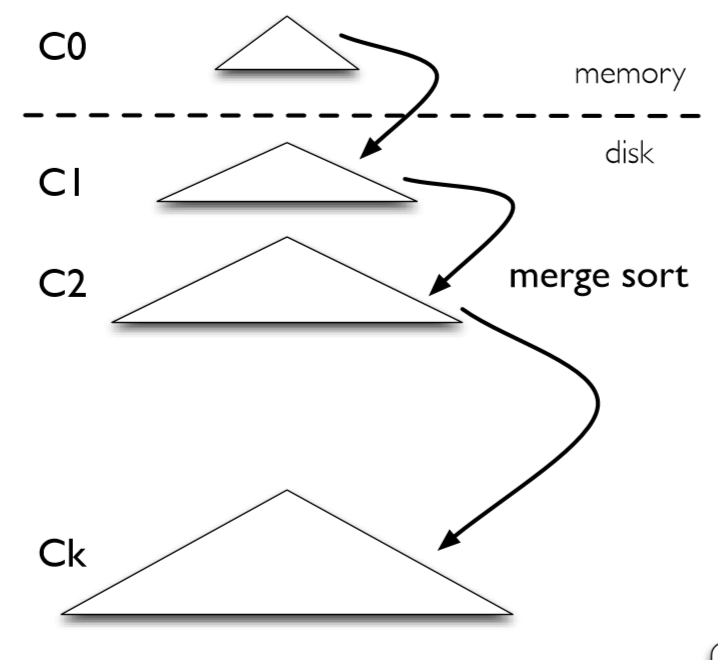
如图所示,为LSM的存储模式,$C_0$为内存中的结构,$C_1$-$C_k$为硬盘中的结构。$C_0$一般是普通的键值数据结构(红黑树、AVL等),$C_i$(i>=1)原始论文用的是Append-Only B-Tree。每一层的大小逐渐递增,各自具有一个size limit。
Insert
在插入的时候,先写入到硬盘中的顺序Log中保证落盘。
然后数据写入到$C_0$中,由于$C_0$是在内存中的,所以本身就是可以高效操作的。$C_0$的大小达到限制之后,合并压缩到下一层的硬盘$C_1$去。
硬盘中的任意一层达到了大小限制之后,也会异步地向下一层合并压缩。
合并压缩保证了文件数量不会过多,造成查询时需要遍历多个文件的情况。
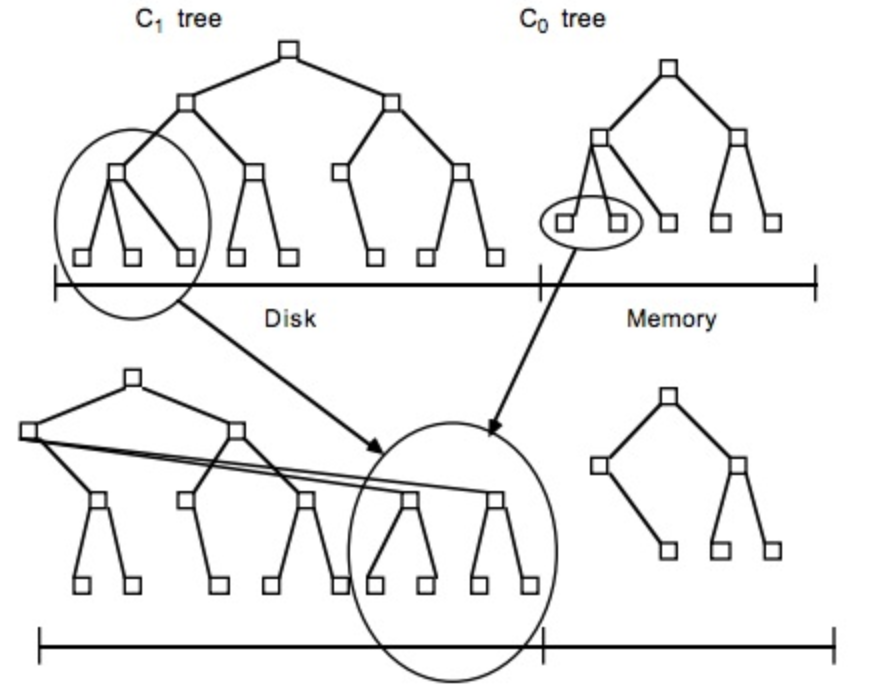
合并的具体过程类似于一个分批的Merge Sort:
- 读取$C_1$的未合并叶子节点到emptying block(内存中)
- 从小到大找$C_0$中的节点和emptying block里进行归并排序,结果保存到filling block(内存中)
- 当filling block满了之后,append到磁盘上。
- 当emptying block空了就从$C_1$里读取数据。
最后得到下图的效果:
Delete
删除则是通过在内存中进行标记。遍历$C_0$树,如果这个节点在$C_0$上,就直接标记。如果不在,就创建一个特殊的带标记结点。
在查询的时候,只要找到带标记的这种节点,就知道完成了删除(因为存储的内容是有顺序信息的),将删除转化为了一种特殊的insert。
Lookup
查询时先从$C_0$中查询,然后逐级向下查询,直到找到为止。
很明显这样的读相对原地更新的数据结构是要慢很多的。
进一步地优化读取,也有Bloom Filter,或增加Cache等方法。
因为可用的内存的增加,通过操作系统提供的大文件缓存,读操作自然会被优化。写性能(内存不可提高)因此变成了主要的关注点,所以采取其它的方法,硬件提升为读性能做的更多,相对于写来说。因此选择一个写优化的文件结构很有意义。
LevelDB
LevelDB就是一个基于LSM的DB Engine。在LevelDB中,$C_0$层由两个memtable组成,其他于硬盘的层称作SSTable。
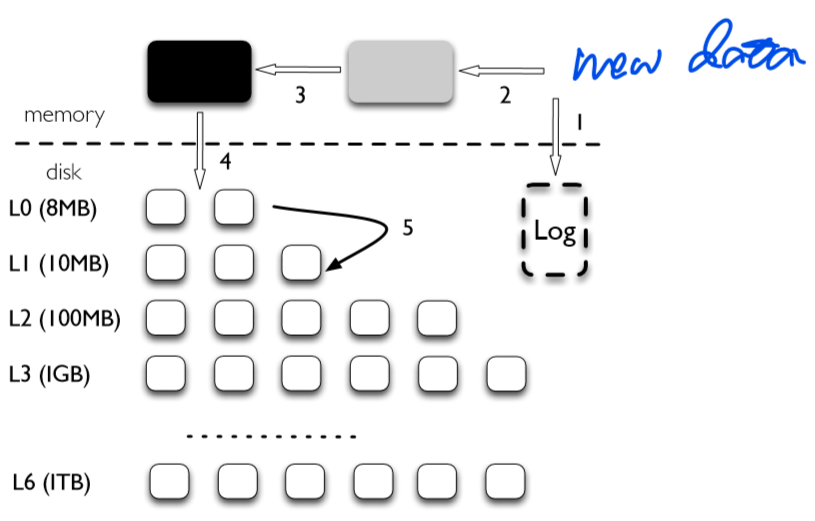 图为LevelDB架构的简单示意图
图为LevelDB架构的简单示意图
遵循LSM的思想,每次插入时,写入log后放到第一个memtable中,当这个memtable满了之后,变成一个immutable memtable中,这个immutable memtable会异步flush到硬盘上,成为一个SSTable,然后开辟一个新的memtable和log。
在LevelDB中,每一层的大小从逐渐递增(8MB->10MB->100MB->1GB),同时单层内除了单树大小的限制,允许有多个树(or 文件),也有一个对应数量限制。
在查找的时候,查找顺序为,memtable->immutable memtable->$L_0$~$L_6$。需要注意的是,$L_0$保存的只是从内存上flush下来的数据,每个树的key显然会有overlap,所以当查找到$L_0$时,需要遍历$L_0$的所有数据。而其他层的数据在合并得到时,保证不让key重叠,即把key分区到不同的文件。
压缩合并的时机也和LSM有一些不同,是当一层的文件数满了之后,从中选一个合并到下一层,而不是直接通过size来进行合并。
缺点
LSM实现了高效的写性能的代价是十分频繁的压缩合并操作,这个操作引发了严重的写放大问题。在SSD设备上,由于擦除才能写入的特性,LSM对于SSD的寿命有比较大的影响。
参考资料
FAY CHANG,JEFFREY DEAN,SANJAY GHEMAWAT et al.Bigtable: A Distributed Storage System for Structured Data[J].ACM Transactions on Computer Systems,2008,26(2):1-26.