序
GAN作为火热的生成模型方法之一,在大量产出的相关论文工作中却很少能看到令人信服的道理来说明谁比谁优越,反而大部分都是用几张不知道哪里采样来的图片来硬点自己就是有过人之处,也不知道model的hyperparameter挑了多久,找了多久的图片……GAN的目标是为了能够生成high quality的样本,同时不失diversity。前面的文章其实提到了,这两个目标就像查全率查准率一样难以同时兼顾,同时造成了难以制定一个好的标准来说明某一特定GAN model的performance。
Likelihood
最经典的想法就是使用生成数据的极大似然Log Likelihood: (为从真实数据中的样本)。假如说这个值很大,就说明这是一个好的生成器。但因为这个式子表示的是,G产生特定图片几率,所以是无法直接获得的。
为了解决这个问题,我们引入Kernel Density Estimation的方法,我们让G产生定量的样本,把这些样本(高维向量)作为一堆固定协方差高斯分布的平均值,我们就能拿出一个混合高斯模型来计算。这个方法的困难之处在于样本数量到底要生成多少是不确定的。

使用Likelihood的同时会带来很多问题,其中影响最大的就是Quality和Diversity的度量。举例子,假如G生成的大量High Quality样本,但只要和test data不同,则得到低likelihood评价;再或者现在有一个特定G能低概率(1%)情况下生成High Quality样本,但这样的G在Likelihood作为评价标准的情况下,和100%生成High Quality样本的某个G,评分相差无几(,而一般Log Likelihood值计算出来都是三位数)。
Objective Evaluation
既然Likelihood有这么多问题,那我们干脆拿一个预训练分类器来进行评价打分。 在Quality上,分类器如果能对每个生成样本给出一个集中的分布(即预测概率集中在一个类别上),就说明这张图的质量好。 在Diversity上,分类器接受一批的生成样本,把对应的预测求平均,假如说概率分布足够平均,就说明生成了很多不同的类别。
基于以上的想法,提出一个
两个项都是entropy的形式,x对应生成样本,y代表分类器的分类。 类似的还有Fr'echet Inception Distance,直接比较图片的浅层激活值。
利用分类器的方式,严重依赖于分类器的性能,假如说拿ImageNet训练的分类器,显然就不适用于更为精细的任务(人脸生成等等)
Avoid Copy
我们的评价体系还需要防止G生成和test image一模一样的副本图片。
首先pixel-wise distance的方式是不合适的,已经有实验证明,把图A简单地移动三个像素形成的A',A和A'的距离已经大于A和真实图片中样本的最小距离了。
我们可以采用类似Style Transfer中对于采取低层特征的方式,用预训练分类器的低层output来构建distance。
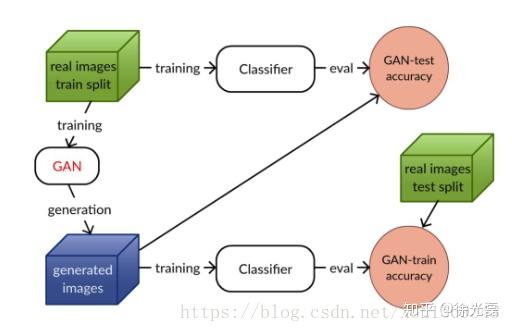
GAN-train & GAN-test
GAN-train & GAN-test的思路是,GAN的目标是能够使生成样本集合的分布和真实样本集合的分布相同,基于这个最终目标,任何一个根据其中一个集合训练出来的分类器,在另一个上,应该也具有同样的准确率。
如下图,GAN-train 根据 GAN 生成图像训练了一个分类器,并在真实图像上进行测试。该指标评估了 GAN 生成图像的多样性和真实性。GAN-test 根据真实图像训练了分类器,并在 GAN 生成图像上进行评估。该指标评估了 GAN 生成图像的真实性。
refer: How good is my GAN?
跋
不知道会不会人会说,我们既然之前设定了很多种的Loss来帮助训练,为什么不直接把Loss来当做评价GAN的标准呢?前文讲到的KL散度、Wasserstein distance难道不能作为评判GAN的标准吗?首先KL散度和Likelihood是一回事。其次Wasserstein distance这样的指标,作为loss的时候,显然是默认作为了本次训练中评价我们模型的一个标准,但当不同的模型有不同的D的时候,这个指标是否可以推广就有点问题了。
GAN的评价标准感觉还是一个比较开放的方向,包括Goodfellow上个月也有新的工作(Skill Rating for Generative Models),可能有一定的窗口吧…